[論文レビュー] PaLI-3 Vision Language Models: Smaller, Faster, Stronger
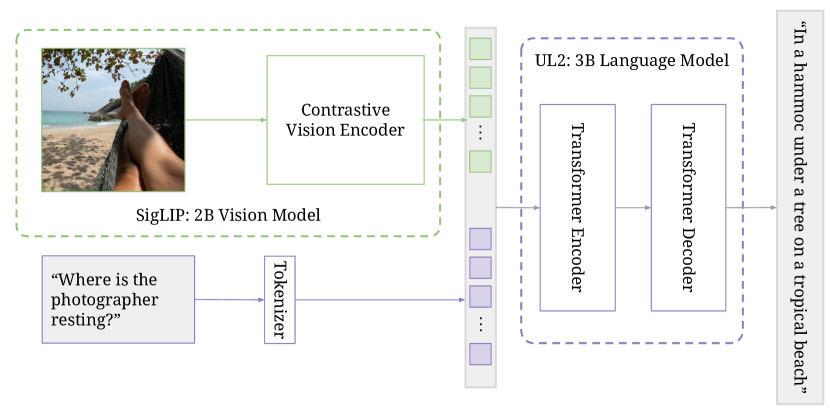
PaLI-3 は SigLIP contrastively pretrained 画像エンコーダを使用する 5B-parameter のビジョン-言語モデルで、SOTA を達成し、多くのマルチモーダルベンチマークで、ローカライゼーションと視覚的配置テキストタスクで、より大きなモデルを上回る。
This paper presents PaLI-3, a smaller, faster, and stronger vision language model (VLM) that compares favorably to similar models that are 10x larger. As part of arriving at this strong performance, we compare Vision Transformer (ViT) models pretrained using classification objectives to contrastively (SigLIP) pretrained ones. We find that, while slightly underperforming on standard image classification benchmarks, SigLIP-based PaLI shows superior performance across various multimodal benchmarks, especially on localization and visually-situated text understanding. We scale the SigLIP image encoder up to 2 billion parameters, and achieves a new state-of-the-art on multilingual cross-modal retrieval. We hope that PaLI-3, at only 5B parameters, rekindles research on fundamental pieces of complex VLMs, and could fuel a new generation of scaled-up models.
研究の動機と目的
- マルチモーダルタスク全般で高い性能を維持しつつ、効率的でより小型の VLM が必要であることを動機づける。
- 画像エンコーダの対比的事前学習(contrastive pretraining)が、VLM における分類前学習より利点をもたらすかを検討する。
- SigLIP ベースの画像エンコーダ、改良されたマルチモーダルデータ混合、より高解像度の訓練を用いて PaLI-3 を構築し、SOTA を達成する。
- 視覚的配置テキスト理解、一般的な VLM ベンチマーク、動画関連タスク全般に渡って PaLI-3 を評価し、汎化性能を示す。
提案手法
- PaLI フレームワーク内で、分類 pretraining を受けた ViT バックボーンと SigLIP contrastively pretrained ViT を比較する。
- ウェブスケールのノイズのある image-text データ上で SigLIP を用いて画像エンコーダを事前学習し、マルチモーダルデータで 3B UL2 テキストエンコーダ-デコーダを訓練する。
- 訓練中に画像解像度を上げる(812x812 および 1064x1064)し、適切に凍結または非凍結のコンポーネントでタスク固有のファインチューニングを実施する。
- ViT からの視覚トークンを 3B UL2 エンコーダ-デコーダへ統合し、タスク固有のテキスト出力を生成する。
- WebLI データ混合を文書および OCR 指向データで拡充し、視覚的配置テキスト理解を向上させる。
実験結果
リサーチクエスチョン
- RQ1PaLI-3 において、対比的に事前学習された画像エンコーダ(SigLIP)は、分類事前学習済みエンコーダよりマルチモーダルタスク全般で利得をもたらすか?
- RQ2より小型の PaLI-3(5B パラメータ)は、自然界のシーン理解と視覚的配置されたテキストタスクの両方で SOTA を達成できるか?
- RQ3より高解像度の訓練とデータ混合が OCR 重視およびローカライゼーションタスクの性能にどう影響するか?
- RQ4動画事前学習なしでの PaLI-3 の Video QA の性能はどうか、そして動画ベンチマークへの汎化は?
主な発見
- SigLIP ベースの PaLI は、分類 pretraining バックボーンと比較して、視覚的配置テキスト理解とローカライゼーションタスクで優れた性能を示す。
- PaLI-3 は 10 を超える vision-language ベンチマークで SOTA を達成し、現行 SOTA モデルより 10 倍小さく、視覚的配置テキストタスクで顕著な向上を達成。
- モデルは、多言語 SigLIP セットアップで使用される 2B SigLIP 画像エンコーダで、多言語横断的なクロスモーダル検索で新しい SOTA を達成。
- PaLI-3 は、動画 pretraining なしにもいくつかの video QA ベンチマークで新しい SOTA を達成し、強力な汎化能力を示している。
- OCR 入力を無効にしたタスクでも、PaLI-3 はしばしば従来手法を上回り、堅牢な内在OCR能力とマルチモーダル推論能力を強調している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。