[論文レビュー] PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering
論文はMedVInTを紹介し、視覚エンコーダと大規模言語モデルを視覚指示チューニングで整合させた生成型MedVQAモデルを提案するとともに、227kのQAペアと149k画像を含む大規模医療VQAデータセットPMC-VQAを公開します。
Medical Visual Question Answering (MedVQA) presents a significant opportunity to enhance diagnostic accuracy and healthcare delivery by leveraging artificial intelligence to interpret and answer questions based on medical images. In this study, we reframe the problem of MedVQA as a generation task that naturally follows the human-machine interaction and propose a generative-based model for medical visual understanding by aligning visual information from a pre-trained vision encoder with a large language model. We establish a scalable pipeline to construct a large-scale medical visual question-answering dataset, named PMC-VQA, which contains 227k VQA pairs of 149k images that cover various modalities or diseases. We train the proposed model on PMC-VQA and then fine-tune it on multiple public benchmarks, e.g., VQA-RAD, SLAKE, and Image-Clef-2019, significantly outperforming existing MedVQA models in generating relevant, accurate free-form answers. In addition, we propose a test set that has undergone manual verification, which is significantly more challenging, serving to better monitor the development of generative MedVQA methods. To facilitate comprehensive evaluation and comparison, we have maintained a leaderboard at https://paperswithcode.com/paper/pmc-vqa-visual-instruction-tuning-for-medical, offering a centralized resource for tracking progress and benchmarking state-of-the-art approaches. The PMC-VQA dataset emerges as a vital resource for the field of research, and the MedVInT presents a significant breakthrough in the area of MedVQA.
研究の動機と目的
- MedVQAを臨床実践における自由形式の回答を可能にするオープンエンド生成タスクへ再定義する。
- 視覚指示チューニングを通じて医用ビジョンエンコーダと言語モデルを整合させることでMedVInTを開発する。
- 大規模で多様なMedVQAデータセット(PMC-VQA)を構築するスケーラブルなパイプラインを作成し、生成型MedVQAモデルの事前学習における価値を示す。
- PMC-VQAでの事前学習とファインチューニングがVQA-RADとSLAKEで最先端の結果を生み出すことを示し、堅牢なベンチマークのための挑戦的なテストセットを提案する。
提案手法
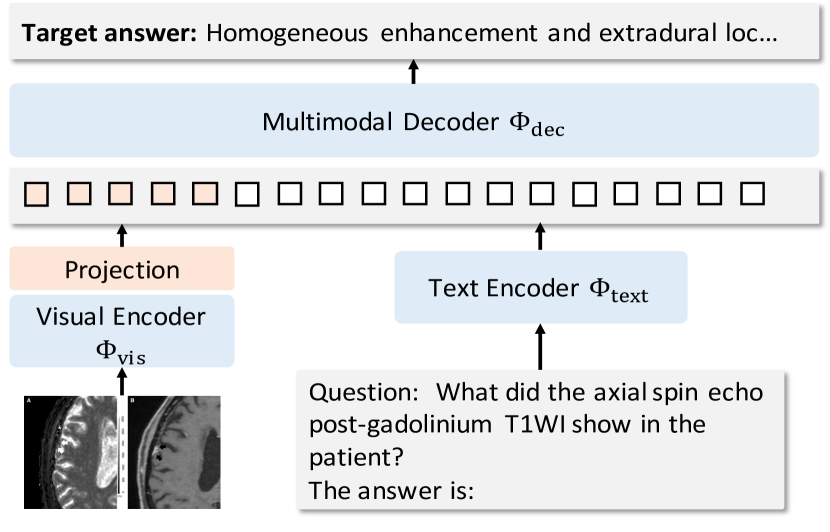
- エンコーダベース(MedVInT-TE)およびデコーダベース(MedVInT-TD)の言語モデルのバリアントを提案する。
- 視覚埋め込みと言語埋め込みを整合させるために学習可能な射影を持つResNet-50ベースの視覚エンコーダを使用する。
- 質問を言語エンコーダでエンコードし、視覚埋め込みと結合してマルチモーダルデコーダへの入力とする(ゼロベースまたは事前学習済みから初期化)。生成をエンコーダベースのLMに対してマスク付き言語モデリングタスクとして定式化する。
- ChatGPTを用いて381Kの画像キャプションペアから1.5Mの質問-回答ペアを生成し、画像関連の回答を保証するQAモデルとキャプションのみの質問を除去する分類器でフィルタリングしてPMC-VQAを構築する。
- PMC-VQAで事前学習を行い、VQA-RADとSLAKEでファインチューニングしてオープンエンド生成とマルチチョイス精度を達成する。
- 公開MedVQAデータセット上で最先端のベースラインと比較し、PMC-VQA-testでのゼロショットおよびファインチューニング性能を評価する。

実験結果
リサーチクエスチョン
- RQ1生成型MedVQAモデルは標準的なMedVQAベンチマークにおいて従来の検索/分類ベースのアプローチを上回ることができるか?
- RQ2医療VQAデータセットによる大規模な視覚指示チューニングはオープンエンドの医療VQA性能を改善するか?
- RQ3PMC-VQAの事前学習はVQA-RAD、SLAKE、およびより難しい新しいベンチマークの性能にどう影響するか?
- RQ4視覚バックボーンと語処理バックボーンおよび射影モジュールの違いがMedVInTの性能にどのように寄与するか?
主な発見
| 手法 | 事前学習データ | VQA-RAD オープン | VQA-RAD クローズ | VQA-RAD 総合 | SLAKE オープン | SLAKE クローズ | SLAKE 総合 |
|---|---|---|---|---|---|---|---|
| MEVF-BAN | – | 49.2 | 77.2 | 66.1 | 77.8 | 79.8 | 78.6 |
| CPRD-BAN | – | 52.5 | 77.9 | 67.8 | 79.5 | 83.4 | 81.1 |
| M3AE | ROCO, MedICaT | 67.2 | 83.5 | 77.0 | 80.3 | 87.8 | 83.3 |
| PMC-CLIP | PMC-OA | 67.0 | 84.0 | 77.6 | 81.9 | 88.0 | 84.3 |
| MedVInT-TE-S | – | 53.6 | 76.5 | 67.4 | 84.0 | 85.1 | 84.4 |
| MedVInT-TD-S | – | 55.3 | 80.5 | 70.5 | 79.7 | 85.1 | 81.8 |
| MedVInT-TE | PMC-VQA | 69.3 | 84.2 | 78.2 | 88.2 | 87.7 | 88.0 |
| MedVInT-TD | PMC-VQA | 73.7 | 86.8 | 81.6 | 84.5 | 86.3 | 85.2 |
- MedVInTはVQA-RADとSLAKEで最先端の正確度を達成し、従来の手法を上回った。
- PMC-VQAでの事前学習は大きな利得をもたらす(TEバリアントでVQA-RAD約11%、SLAKE約4%、TDバリアントでも同様の利得)。
- MedVInT-TEとMedVInT-TDの両方が良好な性能を示し、TDは長いオープンエンド回答で優れ、TEは時に簡潔な回答で上回る。
- PMC-VQA-testは強力なマルチモーダルモデルでも大幅に難易度が高く、改善の余地を示す。
- 医療特化の視覚バックボーンと領域適応済みの言語バックボーンはPMC-VQA評価全体で汎用バックボーンより改善をもたらす。
- 異なる射影モジュール(MLP対Transformer)は同等の性能を示し、埋め込み空間の和解におけるアーキテクチャの柔軟性を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。