[論文レビュー] Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning
この論文では、ピクセル単位の事前学習タスク(具体的にはピクセルから伝搬への一貫性)を導入することで、空間的に感度の高い密な特徴表現を学習する、新しい自己教師付き視覚表現学習手法であるPixProを提案する。標準的な特徴と、同じピクセルの特徴を滑らかに伝搬させたバージョンの間の一貫性を促進することで、PixProは、オブジェクト検出やセマンティックセグメンテーションなどの下流の密予測タスクにおいて、最先端の転移性能を達成し、インスタンスレベルの対照的学習手法を上回って、Pascal VOCでは2.6 AP、COCOでは0.8–1.0 mAPの向上を達成した。
Contrastive learning methods for unsupervised visual representation learning have reached remarkable levels of transfer performance. We argue that the power of contrastive learning has yet to be fully unleashed, as current methods are trained only on instance-level pretext tasks, leading to representations that may be sub-optimal for downstream tasks requiring dense pixel predictions. In this paper, we introduce pixel-level pretext tasks for learning dense feature representations. The first task directly applies contrastive learning at the pixel level. We additionally propose a pixel-to-propagation consistency task that produces better results, even surpassing the state-of-the-art approaches by a large margin. Specifically, it achieves 60.2 AP, 41.4 / 40.5 mAP and 77.2 mIoU when transferred to Pascal VOC object detection (C4), COCO object detection (FPN / C4) and Cityscapes semantic segmentation using a ResNet-50 backbone network, which are 2.6 AP, 0.8 / 1.0 mAP and 1.0 mIoU better than the previous best methods built on instance-level contrastive learning. Moreover, the pixel-level pretext tasks are found to be effective for pre-training not only regular backbone networks but also head networks used for dense downstream tasks, and are complementary to instance-level contrastive methods. These results demonstrate the strong potential of defining pretext tasks at the pixel level, and suggest a new path forward in unsupervised visual representation learning. Code is available at \url{https://github.com/zdaxie/PixPro}.
研究の動機と目的
- 現在のインスタンスレベルの対照的学習手法には、オブジェクト検出やセマンティックセグメンテーションのような密予測タスクに最適でない表現が生じるという限界があることに対処する。
- 画像レベルの手法と比較して、ピクセルレベルで事前学習タスクを定義することで、空間的に感度の高い表現が得られるかどうかを検討する。
- 密予測タスクで使用されるバックボーンネットワークだけでなく、ヘッドネットワークの自己教師付き学習フレームワークを開発する。
- ピクセルレベルとインスタンスレベルの事前学習タスクの相補性が、下流の転移性能を向上させるかどうかを調査する。
- 特に半教師あり学習において、限られたラベル付きデータの環境下で、ピクセルレベルの事前学習がどれほど有効であるかを実証する。
提案手法
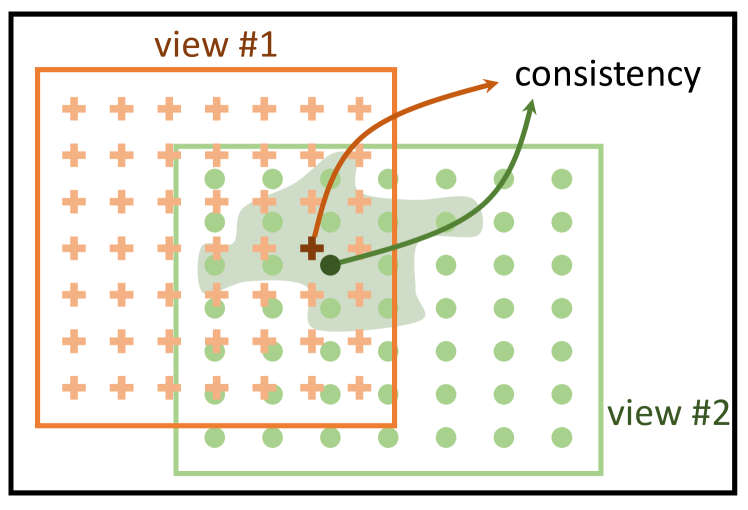
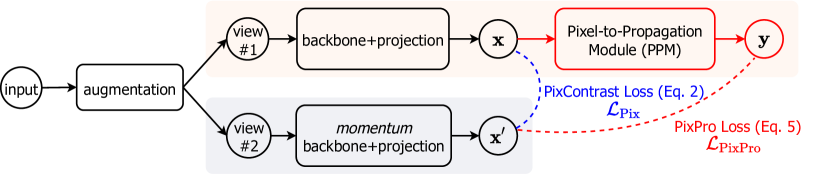
- 各ピクセルを固有のクラスとみなすピクセルレベルの対照的学習手法であるPixContrastを提案する。正例ペアは、2つのランダムなクロップにおける同じピクセルの特徴から形成される。
- 標準的なバックボーンと、類似するピクセルを用いて特徴を滑らかに伝搬させるピクセル伝搬モジュールを備えた2つの非対称なストリームを持つ、ピクセルから伝搬への一貫性を用いるPixProを導入する。
- ピクセル間の類似度に基づいて特徴重みを計算する伝搬モジュールを設計し、フィルタリングと特徴の平滑化を実行することで、元の特徴と一貫性のある正例ペアを生成する。
- 標準的表現と伝搬表現の間の一貫性を促進する対照的損失を用いてモデルを訓練する。これにより、負例ペアを明示的にモデル化する必要がなくなる。
- 提案されたピクセルレベルの事前学習タスクを、インスタンスレベルの対照的学習(例:SimCLR*)と組み合わせることで、空間的感度と分類能力の両方の優位性を活用する。
- バックボーンとヘッドネットワーク(例:FPNと検出ヘッド)を同じピクセルレベルの事前学習タスクで事前学習することで、下流の密予測タスクにおけるより良い初期化を実現する。
実験結果
リサーチクエスチョン
- RQ1ピクセルレベルで事前学習タスクを定義することで、オブジェクト検出やセマンティックセグメンテーションのような密予測タスクに適したより良い表現が得られるか?
- RQ2直接的なピクセルレベルの対照的学習と比較して、ピクセルから伝搬への一貫性は、下流の性能および表現品質においてどのように差をつけるか?
- RQ3ピクセルレベルの事前学習タスクが、通常インスタンスレベルの対照的学習では事前学習されないヘッドネットワークの事前学習をどの程度向上できるか?
- RQ4ピクセルレベルとインスタンスレベルの事前学習タスクを組み合わせることで、転移性能に相乗効果が得られるか?
- RQ5限られたラベル付きデータの半教師あり学習環境下で、ピクセルレベルの事前学習はどの程度有効か?
主な発見
- PixProは、Pascal VOCオブジェクト検出(Faster R-CNN R50-C4)で60.2 mAPを達成し、前回の最良手法を2.6 AP上回った。
- COCOオブジェクト検出では、FPNで41.4 mAP、C4で40.5 mAPを達成し、それぞれ前回のSOTAを0.8 mAPおよび1.0 mAP上回った。
- インスタンスレベルの対照的学習(SimCLR*)と組み合わせた場合、Pascal VOCで58.7 mAP、COCOで40.9 mAPを達成し、相補的な向上効果を示した。
- FPNおよび検出ヘッドを含むヘッドネットワークの事前学習により、COCOオブジェクト検出のFCOSで1.2 mAPの向上が得られ、エンドツーエンドの事前学習の利点を示した。
- COCOで1%のラベル付きデータを用いた半教師ありオブジェクト検出では、PixProで14.8 mAPを達成し、従来の無教師学習手法よりも+3.9 mAPの向上を示した。
- COCOでピクセルレベルのタスクを追加で事前学習することで、1%データでは+0.7 mAP、10%データでは+0.2 mAPの向上が得られ、低データ環境下での強力な利点を示した。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。