[論文レビュー] RAG-Driver: Generalisable Driving Explanations with Retrieval-Augmented In-Context Learning in Multi-Modal Large Language Model
RAG-Driver は、検索補強付きのインコンテキスト学習を用いた多モーダル大規模言語モデルを提案し、ファインチューニングなしで未知環境へ強いゼロショット一般化を実現しつつ、運転行動の説明、正当化、および次の操作予測を提供する。
We need to trust robots that use often opaque AI methods. They need to explain themselves to us, and we need to trust their explanation. In this regard, explainability plays a critical role in trustworthy autonomous decision-making to foster transparency and acceptance among end users, especially in complex autonomous driving. Recent advancements in Multi-Modal Large Language models (MLLMs) have shown promising potential in enhancing the explainability as a driving agent by producing control predictions along with natural language explanations. However, severe data scarcity due to expensive annotation costs and significant domain gaps between different datasets makes the development of a robust and generalisable system an extremely challenging task. Moreover, the prohibitively expensive training requirements of MLLM and the unsolved problem of catastrophic forgetting further limit their generalisability post-deployment. To address these challenges, we present RAG-Driver, a novel retrieval-augmented multi-modal large language model that leverages in-context learning for high-performance, explainable, and generalisable autonomous driving. By grounding in retrieved expert demonstration, we empirically validate that RAG-Driver achieves state-of-the-art performance in producing driving action explanations, justifications, and control signal prediction. More importantly, it exhibits exceptional zero-shot generalisation capabilities to unseen environments without further training endeavours.
研究の動機と目的
- RA-ICLを用いた多モーダルLLM内での検索補強付きインコンテキスト学習を活用することにより、エンドツーエンド自動運転における説明性と一般化能力の不足に対処する。
- 専門家のデモンストレーションの retrieved を用いて運転判断を根拠づけ、行動の説明・正当化・制御信号予測を改善する。
- 追加の訓練なしで未知環境への強力なゼロショット一般化を示す。
- 運転の説明ベンチマークで最先端の性能を示し、制御予測精度も競争力がある。
提案手法
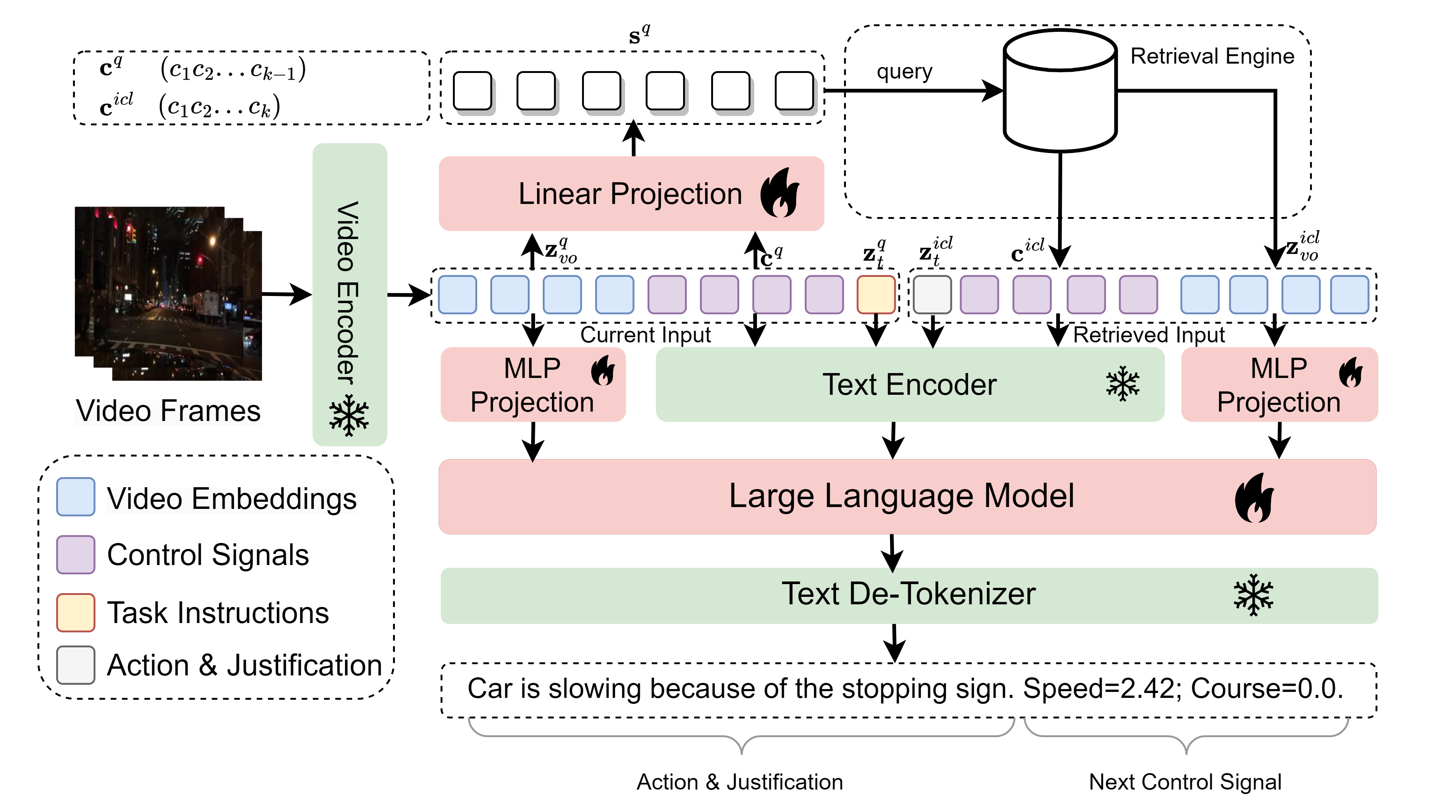
- ビデオ入力とテキスト指示から、運転行動の説明・正当化・次の制御信号を共同で予測する多モーダルLLMのバックボーン(Vicuna 1.5)を使用する。
- 事前学習済みのビデオエンコーダ(LanguageBind)と2層MLPプロジェクターを採用し、視覚埋め込みを言語トークンへ整合させるためのモダリティ間のグラウンディングを実現する。
- 専門家の説明と正当化を付与したハイブリッド埋め込み(動画 + 制御信号)のメモリデータベースを構築し、検索のためのハイブリッド埋め込み空間をトリプレット損失で学習する。
- memories から類似2つの運転体験を取得し、それらをクエリの前置としてMLLMで処理し、推論時の暗黙のメタ最適化を可能にするRA-ICLを実装する。
- 2段階で訓練: (i) VIDAL-10Mでの視覚と言語の整合性を用いた事前訓練、(ii) 三つのタスク(行動の説明、行動の正当化、次の制御信号予測)に特化した16KのQAペアを用いたBDD-Xによる監督付きインコンテキスト指示チューニング。
- ハイブリッド埋め込み空間でコサイン類似度を計算して、RA-ICLのために最も関連性の高い2つのサンプルを取得する検索メカニズムを活用する。
実験結果
リサーチクエスチョン
- RQ1ファインチューニングなしで、未知環境における運転判断の説明性(行動の説明と正当化)を、検索補強付きMLLMによるRA-ICLで改善できるか?
- RQ2 retrieved expert demonstrations に基づく根拠付けは、エンドツーエンドの運転タスクにおける次の制御信号予測(進路と速度)の精度を高めるか?
- RQ3運転状況での検索において、ハイブリッド(動画 + 制御)埋め込みと視覚のみ埋め込みの影響はどうか?
- RQ4運転タスクのためのMLLMにおける効果的なインコンテキスト学習には監督付きファインチューニングが必要か、それとも適切なメモリとプロンプトでゼロショットRA-ICLが十分か?
- RQ5既存の手法と比べて、分布外の運転環境へのRA-ICLのゼロショット一般化性能はどれほどか?
主な発見
- RAG-Driver は BDD-X ベンチマークで最先端の自省的な運転説明性能を達成。
- BDD-X のみで訓練した場合、専門家ベースおよび一部MLLMベースの手法と比較して競争力のある、または優れた行動説明と正当化を提供。
- RA-ICLは、ハイブリッド検索を用いて複数の許容誤差レベルとRMSEに渡って、DriveGPT4を含むベースラインを大幅に上回り、制御信号予測(進路と速度)を大幅に改善。
- アブレーションでは、ハイブリッド類似性(動画 + 制御のハイブリッド)が視覚のみの類似性を上回り、訓練時ICLと推論時ICLの両方が有益であることを示す。
- 本モデルは、BDD-X から構築されたメモリデータベースを用いて未見の環境(Spoken-SAX)へ強力なゼロショット一般化を示し、堅牢な一般化を示す。
- 定性的結果は、夜間・悪天候下でも理解しやすく人間が理解できる説明と正当化を示し、実用的な説明可能性を支持する。
![Figure 2 : Video Encoder architecture. Video is first split into $k\times 32\times 32$ patches concatenated in time, where these patches are linear projected to video embedding. Then, the model is trained with video-language contrastive learning (CLIP4clip) [ 49 ] to obtain language-align video repr](https://ar5iv.labs.arxiv.org/html/2402.10828/assets/images/RAGDriver_ViT.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。