[論文レビュー] RAGBench: Explainable Benchmark for Retrieval-Augmented Generation Systems
RAGBench は、取得強化生成(RAG)に対する大規模な100kサンプルのベンチマークと、 ground-truth アノテーションを用いて複数のドメインにわたる RAG システムを評価する TRACe 評価フレームワーク(Utilization, Relevance, Adherence, Completeness)を導入します。
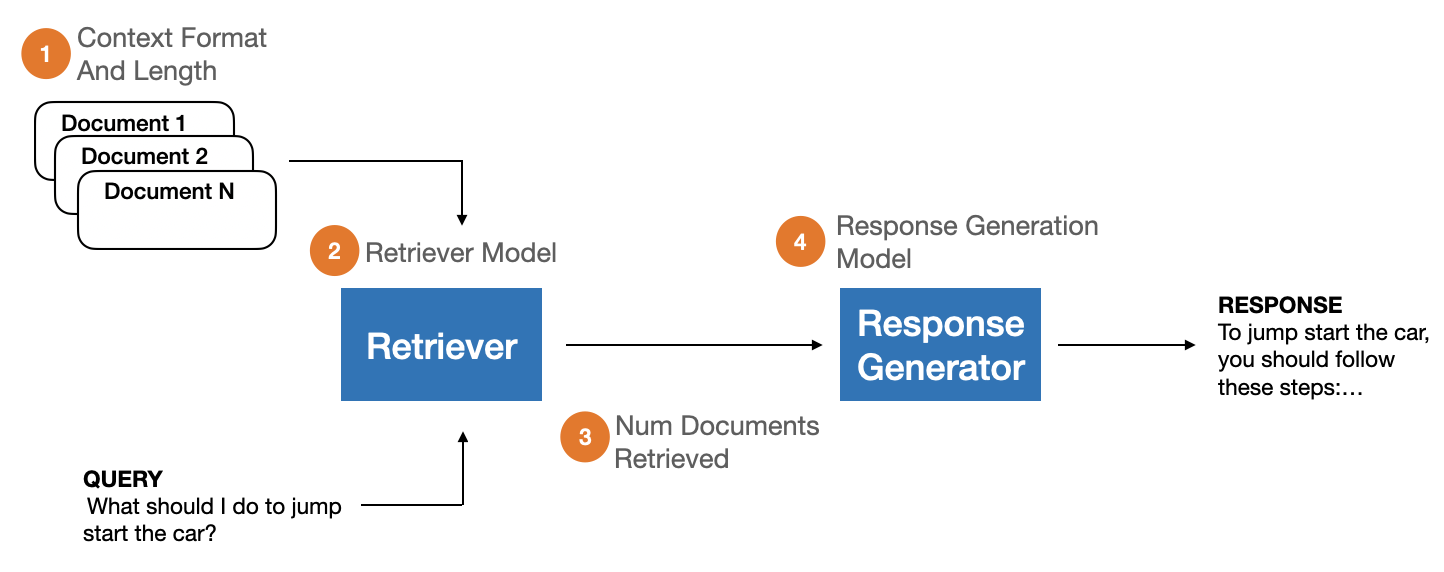
Retrieval-Augmented Generation (RAG) has become a standard architectural pattern for incorporating domain-specific knowledge into user-facing chat applications powered by Large Language Models (LLMs). RAG systems are characterized by (1) a document retriever that queries a domain-specific corpus for context information relevant to an input query, and (2) an LLM that generates a response based on the provided query and context. However, comprehensive evaluation of RAG systems remains a challenge due to the lack of unified evaluation criteria and annotated datasets. In response, we introduce RAGBench: the first comprehensive, large-scale RAG benchmark dataset of 100k examples. It covers five unique industry-specific domains and various RAG task types. RAGBench examples are sourced from industry corpora such as user manuals, making it particularly relevant for industry applications. Further, we formalize the TRACe evaluation framework: a set of explainable and actionable RAG evaluation metrics applicable across all RAG domains. We release the labeled dataset at https://huggingface.co/datasets/rungalileo/ragbench. RAGBench explainable labels facilitate holistic evaluation of RAG systems, enabling actionable feedback for continuous improvement of production applications. Thorough extensive benchmarking, we find that LLM-based RAG evaluation methods struggle to compete with a finetuned RoBERTa model on the RAG evaluation task. We identify areas where existing approaches fall short and propose the adoption of RAGBench with TRACe towards advancing the state of RAG evaluation systems.
研究の動機と目的
- 多様なドメインにわたる取得強化生成(RAG)システムの標準化評価を促進する。
- 複数の産業をカバーする大規模で実世界の RAG ベンチマーク(100k サンプル)を提供する。
- TRACe フレームワークを定義し、リトリーバーとジェネレーターの構成要素が RAG の品質に貢献する度合いを定量化する。
- 粒度が高く説明可能なラベルを通じて、システム改善のための実用的なフィードバックを可能にする。
提案手法
- 生物医薬、一般知識、法務、カスタマーサポート、金融など12のソースから構成要素データセットを収集し、RAG形式に統合する。
- RAG パラメータ(コンテキスト長、取得文書数、ドメイン、生成モデル)を変化させ、実運用環境を模擬する。
- チェーン・オブ・ソート思考技法を用いた GPT-4-turbo プロンプトを用いて、 ground-truth の関連性、利用度、適合性のトークンをアノテーションし、Completeness はスパンから導出する。
- TRACe 指標を提案する:Context Relevance、Context Utilization、Completeness、Adherence、トークンスパンに基づく正式な定義を用いる。
- 既存の RAG 評価手法(LLM 判定、RAGAS、TruLens)と、RAGBench 上の微調整済み DeBERTa ベースの評価器を評価する。
- LLM 判定が、TRACe 指標で微調整済みの専門モデルにしばしば劣ることを示すベンチマーク比較を提供する。
実験結果
リサーチクエスチョン
- RQ1大規模で多ドメインの RAG ベンチマークは、リトリーバーとジェネレーターの構成要素の一貫した評価を可能にするか。
- RQ2説明可能な TRACe 指標(Utilization, Relevance, Adherence, Completeness)は、実運用RAGシステムの改善に実用的な指針を提供するか。
- RQ3ゼロショット/ファショットの LLM 判定と、微調整された識別モデルを、ドメイン横断の RAG 評価で比較するとどうなるか。
- RQ4RAGBench における文脈関連性と利用の予測難易度の相対的な差は何か。
- RQ5小型モデル(例:DeBERTa-large)を微調整することは、多くのデータセットでLLMベースの評価器を上回るか。
主な発見
| データセット | Hal_GPT3.5 | Rel_GPT3.5 | Util_GPT3.5 | Hal_RAGAS | Rel_RAGAS | Util_RAGAS | Hal_TruLens | Rel_TruLens | Util_TruLens | Hal_DeBERTA | Rel_DeBERTA | Util_DeBERTA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PubMedQA | 0.51 | 0.21 | 0.16 | 0.54 | 0.37 | - | 0.62 | 0.45 | - | 0.80 | 0.26 | 0.17 |
| CovidQA-RAG | 0.57 | 0.18 | 0.11 | 0.58 | 0.17 | - | 0.62 | 0.58 | - | 0.77 | 0.19 | 0.11 |
| HotpotQA | 0.59 | 0.11 | 0.08 | 0.62 | 0.14 | - | 0.64 | 0.73 | - | 0.85 | 0.11 | 0.08 |
| MS Marco | 0.65 | 0.23 | 0.11 | 0.63 | 0.25 | - | 0.62 | 0.61 | - | 0.70 | 0.22 | 0.10 |
| HAGRID | 0.58 | 0.22 | 0.15 | 0.62 | 0.22 | - | 0.67 | 0.69 | - | 0.81 | 0.20 | 0.13 |
| ExpertQA | 0.55 | 0.31 | 0.23 | 0.57 | 0.28 | - | 0.70 | 0.60 | - | 0.87 | 0.18 | 0.11 |
| DelucionQA | 0.57 | 0.18 | 0.10 | 0.70 | 0.22 | - | 0.55 | 0.64 | - | 0.64 | 0.15 | 0.10 |
| EManual | 0.54 | 0.17 | 0.11 | 0.57 | 0.27 | - | 0.61 | 0.64 | - | 0.76 | 0.13 | 0.13 |
| TechQA | 0.51 | 0.10 | 0.05 | 0.52 | 0.12 | - | 0.57 | 0.70 | - | 0.86 | 0.08 | 0.04 |
| FinQA | 0.57 | 0.10 | 0.13 | 0.57 | 0.06 | - | 0.53 | 0.79 | - | 0.81 | 0.10 | 0.10 |
| TAT-QA | 0.52 | 0.20 | 0.17 | 0.63 | 0.18 | - | 0.59 | 0.72 | - | 0.83 | 0.27 | 0.23 |
| CUAD | 0.51 | 0.27 | 0.11 | 0.66 | 0.19 | - | 0.40 | 0.66 | - | 0.80 | 0.24 | 0.10 |
- RAGBench は、長文コンテキスト CUAD および数値的に豊富な FinQA/TAT-QA を含む、5つのドメインにまたがる12のコンポーネントデータセットからなる100kサンプルを含む。
- TRACe 指標は、生成回答のリトリーバー関連性、文脈利用、適合性、完結度を粒度の高い評価を可能にする。
- 微調整済みの DeBERTa-large は、多くのデータセットでゼロショット LLM 判定を TRACe 指標で上回る。
- 文脈関連性は予測が難しく(RMSE が高い)、正しい回答に必要な文脈を特定する難しさを反映している。
- LLM 判定(GPT-3.5、RAGAS、TruLens)は、微調整済みの専門モデルに対して競争力はあるが、必ずしも普遍的な性能ではない。
- GPT-4-turbo による RAGBench のアノテーションは、シミュレートデータでグラウンドトゥルースとの Kendall の tau 相関が高く、アノテーションの有効性を裏付けている。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。