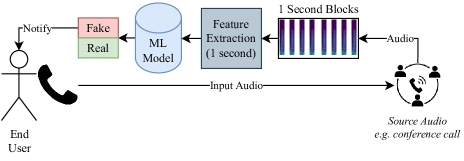
[論文レビュー] Real-time Detection of AI-Generated Speech for DeepFake Voice Conversion
本論文は、実音声とAI生成音声のDEEP-VOICEデータセットを作成し、統計的音声特徴を分析し、RVCベースのボイスコンバージョンを検出する際にXGBoostがリアルタイム0.004 ms推論で1秒間の音声区間に対して99.3%の精度を達成することを示す。
There are growing implications surrounding generative AI in the speech domain that enable voice cloning and real-time voice conversion from one individual to another. This technology poses a significant ethical threat and could lead to breaches of privacy and misrepresentation, thus there is an urgent need for real-time detection of AI-generated speech for DeepFake Voice Conversion. To address the above emerging issues, the DEEP-VOICE dataset is generated in this study, comprised of real human speech from eight well-known figures and their speech converted to one another using Retrieval-based Voice Conversion. Presenting as a binary classification problem of whether the speech is real or AI-generated, statistical analysis of temporal audio features through t-testing reveals that there are significantly different distributions. Hyperparameter optimisation is implemented for machine learning models to identify the source of speech. Following the training of 208 individual machine learning models over 10-fold cross validation, it is found that the Extreme Gradient Boosting model can achieve an average classification accuracy of 99.3% and can classify speech in real-time, at around 0.004 milliseconds given one second of speech. All data generated for this study is released publicly for future research on AI speech detection.
研究の動機と目的
- リアルタイム通信におけるプライバシー侵害と誤表現を防ぐために、AI生成音声を検出する必要性を動機づける。
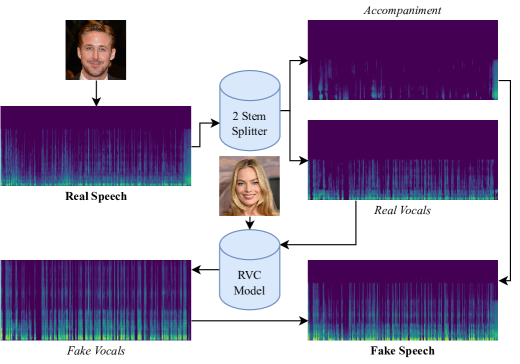
- Retrieval-based Voice Conversion (RVC) を用いて、八名の公人の実声とAI生成音声を含むオリジナルデータセット(DEEP-VOICE)を作成する。
- 実声とAI生成音声を区別する音声特徴の統計的有意性を分析する。
- リアルタイム検出を可能にするため、ハイパーパラメータ最適化を伴う複数の機械学習モデルを評価する。
提案手法
- 8名の個人から62分22秒の実声と、Retrieval-based Voice Conversionを用いたAI生成音声を含むDEEP-VOICEデータセットを生成する。
- クロマグラム、MFCC、スペクトル特徴、ZCR、 RMS を含む1秒ごとのセグメントから26の音声特徴を抽出する。
- 実サンプルと同じ比率になるよう、偽(AI生成)サンプルをアンダーサンプリングしてデータを1:1にバランスさせる。
- 10-foldクロスバリデーションとシード42で、XGBoost、Random Forest、QDA、LDA、Ridge、Gaussian Naive Bayes、Bernoulli NB、KNN、SVM、SGD、Gaussian Process などの機械学習モデルのスイートを訓練・評価する。
- XGBoost(330ラウンドが最適)、Random Forest(310本のツリー)、KNN(1近傍が最適)をハイパーパラメータ最適化し、推論時間を報告(1秒あたり0.004–0.057 ms)。
- Accuracy、precision、recall、F1、MCC、ROC AUC などの指標で性能を評価する。
実験結果
リサーチクエスチョン
- RQ1Retrieval-based Voice Conversion によって生成された AI 音声と実在人の音声をリアルタイム検出で識別できるか。
- RQ2どの音声特徴が実声とAI生成音声を最も識別するのか、リアルタイム制約下で異なるMLモデルはどのように性能を発揮するか。
- RQ3ハイパーパラメータがDeepFakeボイス変換のリアルタイム検出の精度と推論時間にどのように影響するか。
- RQ4通話や会議中にAI生成音声を検出して警告するリアルタイム警告システムを展開することは実現可能か。
主な発見
- XGBoostは330回のブースティングラウンドで、10-foldクロスバリデーションで99.3%の精度を達成(precision 0.995、recall 0.991、F1 0.993、MCC 0.986、ROC AUC 0.993)。
- 1秒の音声に対する推論時間はXGBoostで平均0.004 ms。
- 310本の木を持つRandom Forestは98.89%の精度を達成(precision 0.995、recall 0.983、F1 0.989、MCC 0.978、ROC AUC 0.989)で、1秒あたり0.057 ms。
- KNN(1近傍)は0.143 ms/秒で81.48%の精度を達成し、QDAは0.002 msの推論で94.8%の精度を提供。
- 総じて、XGBoostとRandom Forestは折りたたみ間で強い一般化性を示し、RVCベースのボイスコンバージョンのリアルタイム検出を可能にする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。