[論文レビュー] RemoteCLIP: A Vision Language Foundation Model for Remote Sensing
RemoteCLIP は、リモートセンシングのためのビジョン-ランゲージ基盤モデルで、Box-to-Caption と Mask-to-Box の変換を用いてデータをスケールさせ、画像とテキストの表現を整合させる。これにより、多様なデータセットに対してゼロショットおよび検索タスクが可能になる。
General-purpose foundation models have led to recent breakthroughs in artificial intelligence. In remote sensing, self-supervised learning (SSL) and Masked Image Modeling (MIM) have been adopted to build foundation models. However, these models primarily learn low-level features and require annotated data for fine-tuning. Moreover, they are inapplicable for retrieval and zero-shot applications due to the lack of language understanding. To address these limitations, we propose RemoteCLIP, the first vision-language foundation model for remote sensing that aims to learn robust visual features with rich semantics and aligned text embeddings for seamless downstream application. To address the scarcity of pre-training data, we leverage data scaling which converts heterogeneous annotations into a unified image-caption data format based on Box-to-Caption (B2C) and Mask-to-Box (M2B) conversion. By further incorporating UAV imagery, we produce a 12 $ imes$ larger pretraining dataset than the combination of all available datasets. RemoteCLIP can be applied to a variety of downstream tasks, including zero-shot image classification, linear probing, $ extit{k}$-NN classification, few-shot classification, image-text retrieval, and object counting in remote sensing images. Evaluation on 16 datasets, including a newly introduced RemoteCount benchmark to test the object counting ability, shows that RemoteCLIP consistently outperforms baseline foundation models across different model scales. Impressively, RemoteCLIP beats the state-of-the-art method by 9.14% mean recall on the RSITMD dataset and 8.92% on the RSICD dataset. For zero-shot classification, our RemoteCLIP outperforms the CLIP baseline by up to 6.39% average accuracy on 12 downstream datasets. Project website: https://github.com/ChenDelong1999/RemoteCLIP
研究の動機と目的
- リモートセンシングにおけるビジョン-ランゲージモデルの事前学習データの不足に対処する。
- 下流タスクのためのリッチな意味論を持つ頑健な視覚特徴と整合したテキスト埋め込みを学習する。
- 統一された image-caption データ形式を介して、リモートセンシングにおけるゼロショット、ファ few-shot、およびリトリーバルベースの応用を可能にする。
- 異種アノテーションを活用した大規模事前学習のためのデータスケーリング手法を実証する。
提案手法
- 画像エンコーダとテキストエンコーダを用いた CLIP 風の対比事前学習で InfoNCE 損失を最適化する。
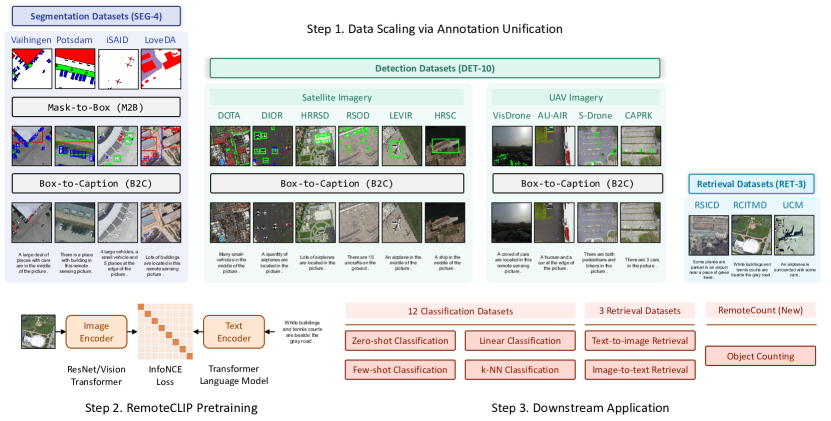
- Box-to-Caption (B2C) 生成と Mask-to-Box (M2B) 変換を通じて、異種のリモートセンシングアノテーションを統合し、画像-テキストペアを作成する。
- DET-10, SEG-4, RET-3、および UAV 画像を組み込むことで、事前学習データを結合オープンデータセットの12倍にスケールする。
- 16 の下流データセットに対して、ゼロショット、リニアプロービング、k-NN、few-shot、画像-テキスト検索タスクで RemoteCLIP を評価する。
- モデルとデータスケールの効果を示すために、複数のバックボーンサイズ(ResNet-50、ViT-Base-32、ViT-Large-14)をサポートする。
- リモートセンシングでの物体カウント用の新しい RemoteCount ベンチマークを提供する。
実験結果
リサーチクエスチョン
- RQ1大規模統一されたリモートセンシングの image-caption データで学習したビジョン-ランゲージ基盤モデルは、多様な下流タスクでドメイン固有のベースラインを上回ることができるか?
- RQ2アノテーションの統合(B2C および M2B)によるデータスケーリングは、リモートセンシングにおけるより強力な意味論的整合と、ゼロショット/few-shot の性能向上をもたらすか?
- RQ3異なるバックボーンサイズは、リモートセンシングにおける分類と検索タスクに対する RemoteCLIP の性能にどのように影響するか?
- RQ4リモートセンシング領域における CLIP ベースモデルにとって、ドメイン内データでの継続的事前訓練は有益か?
- RQ51つのモデルで、複数のリモートセンシングモダリティ(衛星と UAV)およびタスク(カウント、リトリーバル、分類)で高い性能を達成できるか?
主な発見
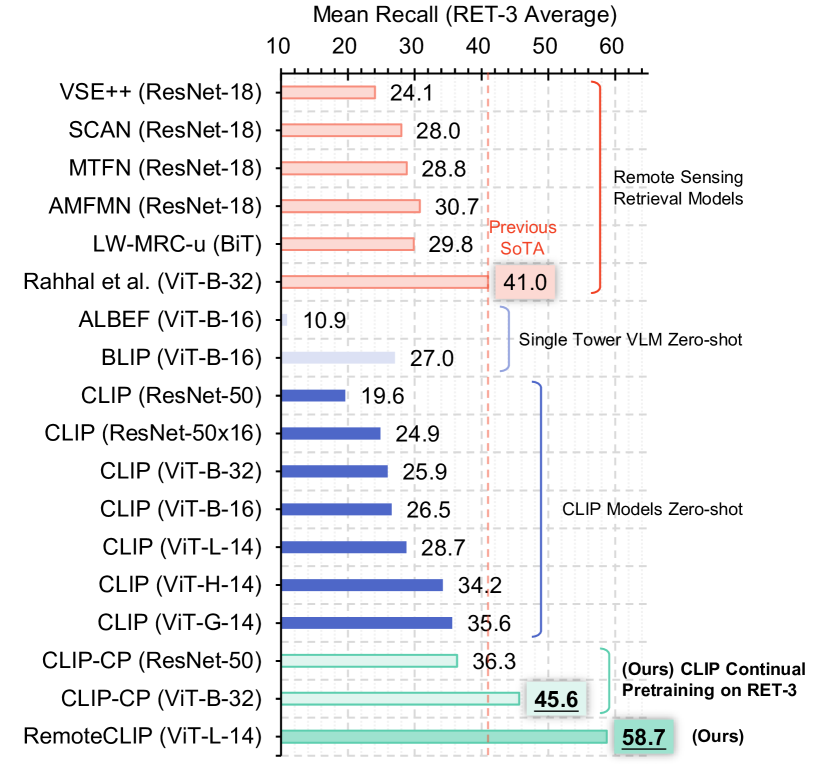
- RemoteCLIP のゼロショット分類性能は、12 の下流データセットの平均精度で CLIP ベースラインを最大で 6.39% 上回る。
- 継続的事前学習(CLIP-CP)は検索ベンチマークを大幅に向上させ、RSITMD、RSICD、UCM で新しい最先端を確立した。
- RET-3/SEG-4/DET-10+ データセットの 12 倍へのデータスケーリングは、小規模な継続的事前学習よりも顕著な向上をもたらした。
- RemoteCLIP は、16 のリモートセンシングデータセットで、ResNet-50 から ViT-Large-14 までのタスクとモデル規模において、ベースラインの基盤モデルを上回る。
- RSITMD および RSICD の向上は、それぞれ平均リコール 9.14%、8.92% の改善を含む。
- このモデルは、ゼロショット、リニアプロービング、k-NN、few-shot分類、画像-テキスト検索の多様なタスクに対して汎用性を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。