[論文レビュー] Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
SETR を提案する、パッチ列として画像を扱う純粋なトランスフォーマーエンコーダでセマンティックセグメンテーションを行い、ADE20KとPascal Contextで最新機能を達成し、Cityscapesの結果も競争力を持つ。
Most recent semantic segmentation methods adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract/semantic visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated/atrous convolutions or inserting attention modules. However, the encoder-decoder based FCN architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating semantic segmentation as a sequence-to-sequence prediction task. Specifically, we deploy a pure transformer (ie, without convolution and resolution reduction) to encode an image as a sequence of patches. With the global context modeled in every layer of the transformer, this encoder can be combined with a simple decoder to provide a powerful segmentation model, termed SEgmentation TRansformer (SETR). Extensive experiments show that SETR achieves new state of the art on ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU) and competitive results on Cityscapes. Particularly, we achieve the first position in the highly competitive ADE20K test server leaderboard on the day of submission.
研究の動機と目的
- エンコーダ-デコーダ FCN アーキテクチャを超えたセマンティックセグメンテーションの再検討。
- 空間解像度のダウンサンプリングを回避する純粋なトランスフォーマーエンコーダを導入する。
- トランスフォーマー特徴量からの全解像度セグメンテーションを回復するデコーダ設計を探る。
- 画像パッチ全体にわたるグローバル自己注意が優れた特徴表現を生み出すことを示す。
提案手法
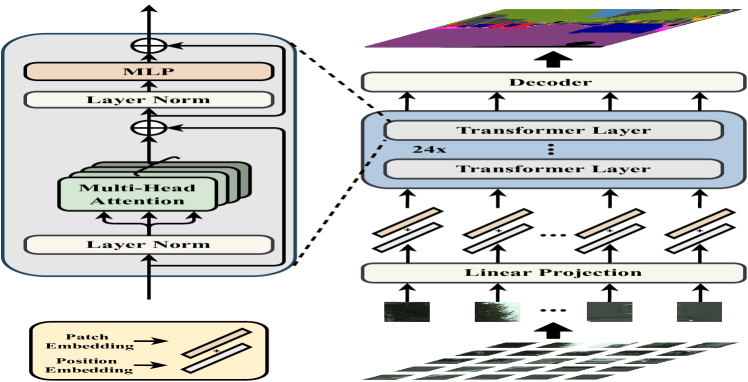
- 画像を固定サイズのパッチに分割し、それらを線形に埋め込んで1Dシーケンスにする。
- グローバル自己注意を用いた純粋な Transformer エンコーダでパッチレベルの特徴を学習する。
- 学習可能なパッチ位置埋め込みを介して空間情報を追加する。
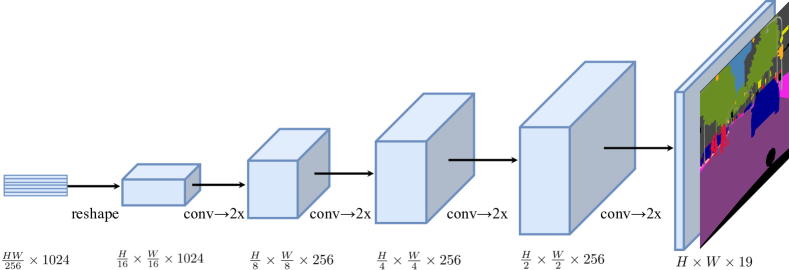
- 3つのデコーダ設計を試す:ナイーブなアップサンプリング、プログレッシブアップサンプリング(PUP)、およびマルチレベル特徴量統合(MLA)。
- 適用可能な箇所で ViT/DeiT を用いてトランスフォーマーのバックボーンを事前学習し、中間のTransformer層に補助損失を組み込む。
実験結果
リサーチクエスチョン
- RQ1画像パッチ上で動作する純粋な Transformer エンコーダはセマンティックセグメンテーションの畳み込みエンコーダを置換できるか。
- RQ2Transformer ベースのエンコーダを使用したとき、異なるデコーダ設計はピクセルレベルのセグメンテーションにどのような影響を与えるか。
- RQ3標準的なセグメンテーションベンチマークにおける SETR の性能に対する事前学習戦略(ViT/DeiT)の影響は何か。
主な発見
- SETR は ADE20K(MS 推論で 50.28% mIoU)と Pascal Context(MS 推論で 55.83% mIoU)で state-of-the-art を達成する。
- SETR は Cityscapes でも競争力のある結果を示し、SETR-PUP は多くの FCN ベースおよび注意機構を用いたベースラインを上回る。
- Transformer エンコーダの事前学習(ViT/DeiT)は性能を大幅に向上させ、ランダム初期化版を上回る。
- 3つのデコーダ設計は異なるトレードオフを示し、プログレッシブアップサンプリング(SETR-PUP)が一般に精度と複雑さのバランスで最良を提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。