[論文レビュー] RoBERTa-BiLSTM: A Context-Aware Hybrid Model for Sentiment Analysis
本論文は RoBERTa-BiLSTM を提案する。これは RoBERTa を用いて語彙埋め込みを生成し、BiLSTM で長距離依存関係を捉えるハイブリッドモデルで、3つのデータセットにわたって感情分析の最先端結果を達成する。
Effectively analyzing the comments to uncover latent intentions holds immense value in making strategic decisions across various domains. However, several challenges hinder the process of sentiment analysis including the lexical diversity exhibited in comments, the presence of long dependencies within the text, encountering unknown symbols and words, and dealing with imbalanced datasets. Moreover, existing sentiment analysis tasks mostly leveraged sequential models to encode the long dependent texts and it requires longer execution time as it processes the text sequentially. In contrast, the Transformer requires less execution time due to its parallel processing nature. In this work, we introduce a novel hybrid deep learning model, RoBERTa-BiLSTM, which combines the Robustly Optimized BERT Pretraining Approach (RoBERTa) with Bidirectional Long Short-Term Memory (BiLSTM) networks. RoBERTa is utilized to generate meaningful word embedding vectors, while BiLSTM effectively captures the contextual semantics of long-dependent texts. The RoBERTa-BiLSTM hybrid model leverages the strengths of both sequential and Transformer models to enhance performance in sentiment analysis. We conducted experiments using datasets from IMDb, Twitter US Airline, and Sentiment140 to evaluate the proposed model against existing state-of-the-art methods. Our experimental findings demonstrate that the RoBERTa-BiLSTM model surpasses baseline models (e.g., BERT, RoBERTa-base, RoBERTa-GRU, and RoBERTa-LSTM), achieving accuracies of 80.74%, 92.36%, and 82.25% on the Twitter US Airline, IMDb, and Sentiment140 datasets, respectively. Additionally, the model achieves F1-scores of 80.73%, 92.35%, and 82.25% on the same datasets, respectively.
研究の動機と目的
- 語彙的多様性・長距離依存・不均衡データの中で、多様なオンラインコメントに対する感情分析の動機付け。
- RoBERTa の埋め込みを BiLSTM と組み合わせた文脈認識型ハイブリッドモデルを提案し、性能向上を図る。
- 複数データセットで RoBERTa-BiLSTM を最先端のベースラインと比較評価する。
- データ前処理とハイパーパラメータ調整がモデル性能に与える影響を分析する。
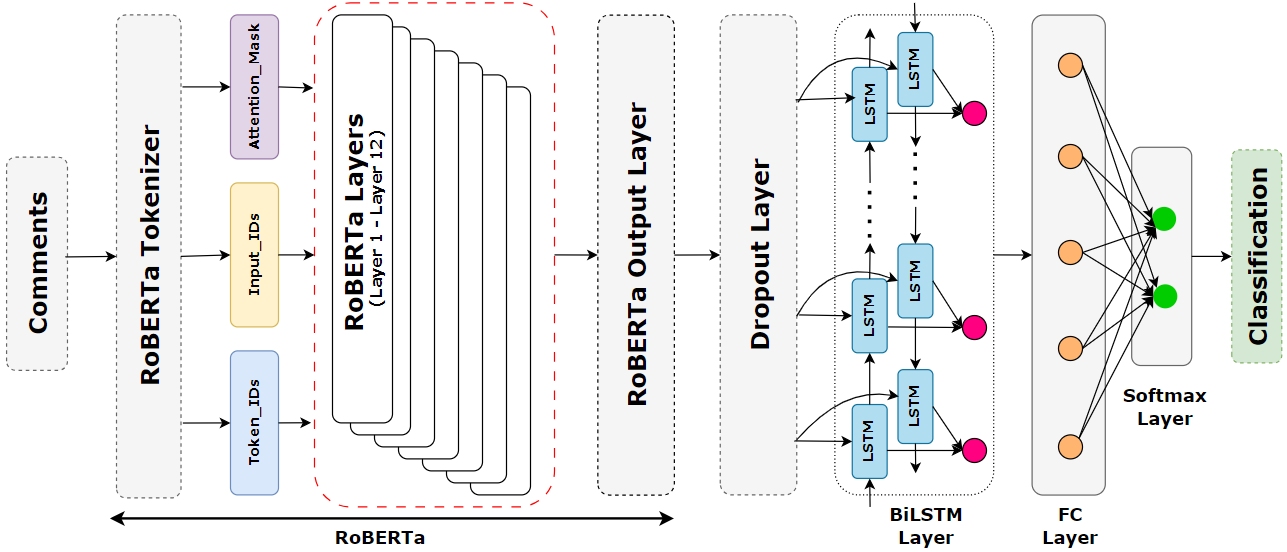
提案手法
- RoBERTa をエンコーダとして用い、文脈的語彙埋め込みを生成する。
- RoBERTa の埋め込みを Dropout 層を伴う BiLSTM に入力し、長距離依存を捉える。
- BiLSTM の出力を感情クラスへ写像するために、密結合層と Softmax 分類器を追加する。
- RoBERTa トークン化の前に、英小文字化・ノイズ除去・レマタイゼーションなどのデータ前処理を適用する。
- ハイパーパラメータ(学習率・隠れ層ユニット)を調整し、LSTM/GRU バリアントと比較する。
- 多クラス感情分類の損失としてクロスエントロピーを使用する。
実験結果
リサーチクエスチョン
- RQ1RoBERTa-BiLSTM ハイブリッドモデルは、感情分析タスクで標準的な RoBERTa バリアント(base, GRU, LSTM)を上回ることができるか?
- RQ2データ前処理の選択とハイパーパラメータ調整がモデル性能に与える影響は何か?
- RQ3IMDb・Twitter US Airline・Sentiment140 など、クラス分布が異なる多様なデータセットでのモデルの性能はどうなるか?
主な発見
- RoBERTa-BiLSTM は Twitter US Airline で 80.74% の精度を達成。
- RoBERTa-BiLSTM は IMDb で 92.36% の精度を達成。
- RoBERTa-BiLSTM は Sentiment140 で 82.25% の精度を達成。
- RoBERTa-BiLSTM は F1 スコアで 80.73%(Twitter US Airline),92.35%(IMDb),82.25%(Sentiment140)を達成。
- 評価データセットにおいて、モデルは RoBERTa-base、RoBERTa-GRU、RoBERTa-LSTM のベースラインを上回る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。