[論文レビュー] RULER: What's the Real Context Size of Your Long-Context Language Models?
RULERは、検索を超える長い文脈の言語モデルを評価するための4つのタスクカテゴリを持つ合成ベンチマークを導入し、文脈長が長くなるにつれてほとんどのモデルが性能を低下させること、そして非常に長い文脈でのみ性能を維持するモデルがわずかであることを示す。
The needle-in-a-haystack (NIAH) test, which examines the ability to retrieve a piece of information (the "needle") from long distractor texts (the "haystack"), has been widely adopted to evaluate long-context language models (LMs). However, this simple retrieval-based test is indicative of only a superficial form of long-context understanding. To provide a more comprehensive evaluation of long-context LMs, we create a new synthetic benchmark RULER with flexible configurations for customized sequence length and task complexity. RULER expands upon the vanilla NIAH test to encompass variations with diverse types and quantities of needles. Moreover, RULER introduces new task categories multi-hop tracing and aggregation to test behaviors beyond searching from context. We evaluate 17 long-context LMs with 13 representative tasks in RULER. Despite achieving nearly perfect accuracy in the vanilla NIAH test, almost all models exhibit large performance drops as the context length increases. While these models all claim context sizes of 32K tokens or greater, only half of them can maintain satisfactory performance at the length of 32K. Our analysis of Yi-34B, which supports context length of 200K, reveals large room for improvement as we increase input length and task complexity. We open source RULER to spur comprehensive evaluation of long-context LMs.
研究の動機と目的
- 長文脈LMを検索タスクの枠を超えて、より包括的に評価する動機づけ。
- さまざまな文脈長とタスクの複雑さを評価する柔軟なベンチマーク(RULER)を提供する。
- 現在のモデルが長い入力で検索、追跡、集約、QAをどのように扱うかを調査する。
- 長文脈理解を妨げたり助けたりする要因と失敗モードを特定する。
提案手法
- 四つのタスクカテゴリと設定可能な文脈長・複雑さを備えた合成ベンチマーク「RULER」を提案する。
- needle-in-a-haystack (NIAH) を複数の検索変種に拡張する(S-NIAH、MK-NIAH、MV-NIAH、MQ-NIAH)。
- Multi-hop Tracing(Variable Tracking)を導入し、長文脈での照応のような連鎖を検証する。
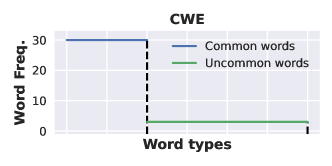
- 長い入力全体の情報統合を評価するためのAggregationタスク(CWEおよびFWE)を追加する。
- 注意をそらす情報を含むQAタスクを組み込み、長文脈での質問応答を評価する。
実験結果
リサーチクエスチョン
- RQ1文脈長が拡大し、含まれる妨害情報が変化した場合、長文脈LMは検索タスクでどのように性能を示すか。
- RQ2モデルは長文脈でマルチホップ追跡とエンティティ追跡を安定して行えるか。
- RQ3長い系列にわたる情報を効果的に統合できるか、Zipf様分布の語彙がこれにどのように影響するか。
- RQ4妨害情報が追加されたとき、文脈サイズはQA性能にどのように影響し、モデルは幻覚を見たりパラメトリック知識に依存したりするか。
主な発見
- 全てのモデルは、文脈長が長くなるにつれて大きな性能低下を示すが、素のNIAHの結果は堅調である。
- ごく一部のモデル(例:GPT-4、Command-R、Yi-34B、Mixtral)は非常に長い文脈(32K)で満足な性能を維持するが、多くは公称の文脈サイズには及ばない。
- 非検索タスク(マルチホップ追跡、集約、QA)は、文脈からの丸写し、パラメトリック知識への依存、情報検索の不完全性など、重大な失敗モードを示す。
- モデルサイズ、訓練時の文脈長、トランスフォーマーのアーキテクチャは長文脈能力に影響を与え、一般に大きなモデルほど性能が良く、非トランスフォーマーアーキテクチャは遅れを取りがちである。
- Yi-34B-200K は、入力長とタスクの複雑さが増すと顕著に性能が低下し、回答の不完全さや関連情報の特定難易度が生じる。
- 訓練時の文脈長を拡張してもRULERの性能が普遍的に向上するわけではなく、未知の長さへ外挿すると顕著な劣化がある。
- このベンチマークは、素のNIAHには含まれない明確な失敗モードを浮き彫りにし、長い文脈のより広範な評価の必要性を強調している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。