[論文レビュー] ServerlessLLM: Low-Latency Serverless Inference for Large Language Models
ServerlessLLM はローカリティを強化したサーバーレス LLM 推論を導入し、 loading-optimized チェックポイントの高速読み込み、ローカリティのためのライブマイグレーション、ローカリティ認識のサーバー割り当てを通じて、実 workloads でベースラインに対して最大 10-200X のレイテンシ改善を達成します。
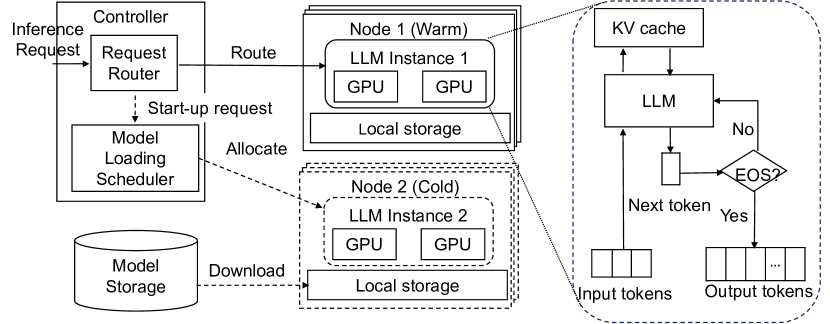
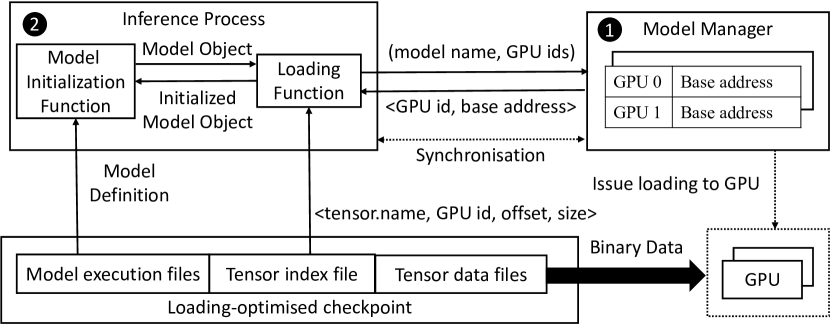
This paper presents ServerlessLLM, a distributed system designed to support low-latency serverless inference for Large Language Models (LLMs). By harnessing the substantial near-GPU storage and memory capacities of inference servers, ServerlessLLM achieves effective local checkpoint storage, minimizing the need for remote checkpoint downloads and ensuring efficient checkpoint loading. The design of ServerlessLLM features three core contributions: (i) \emph{fast multi-tier checkpoint loading}, featuring a new loading-optimized checkpoint format and a multi-tier loading system, fully utilizing the bandwidth of complex storage hierarchies on GPU servers; (ii) \emph{efficient live migration of LLM inference}, which enables newly initiated inferences to capitalize on local checkpoint storage while ensuring minimal user interruption; and (iii) \emph{startup-time-optimized model scheduling}, which assesses the locality statuses of checkpoints on each server and schedules the model onto servers that minimize the time to start the inference. Comprehensive evaluations, including microbenchmarks and real-world scenarios, demonstrate that ServerlessLLM dramatically outperforms state-of-the-art serverless systems, reducing latency by 10 - 200X across various LLM inference workloads.
研究の動機と目的
- 低遅延でスケーラブルなサーバーレス LLM 推論の必要性を動機づけ、ローカルストレージ帯域を活用してGPUの浪費を削減する。
- 最適化されたチェックポイント読み込み、ライブマイグレーション、スマートなサーバー選択を通じて起動遅延を最小化するローカリティ強化サーバーレス LLM システムを設計する。
- モデル起動を加速するロード最適化済みのチェックポイント形式とマルチ tier ロードパイプラインを提案する。
- LLM 推論のためのライブマイグレーションを導入し、進行中の作業を維持しつつローカリティ認識の配置を実現する。
- サーバー割り当てを最適化するためのロード時間推定とマイグレーション時間推定を組み込み、信頼性キー・バリュー・ストアによる状態と障害復旧を導く。
提案手法
- GPU 復元を高速化する連続チャンク読み込みとテンソルアドレス索引を可能にするロード最適化済みチェックポイント形式を開発する。
- インサーバーモデルマネージャとインメモリデータチャンクプール、直接ファイルアクセス、多段階データロードパイプラインを備えたマルチ tier チェックポイント読み込みサブシステムを実装する。
- トークンベースのマイグレーションと進行中の推論を妨げない二段階プロセスに基づく LLM 推論のライブマイグレーションを導入する。
- 信頼性キー値ストアで状態と障害復旧を導く、ロード時間推定器とモデルマイグレーション時間推定器を用いたローカリティ認識サーバー割り当てを提案する。
- 動的計画法とリアルタイム監視を使用して、最適な帯域幅とローカリティを持つサーバーを選択することで起動遅延を最小化する。
実験結果
リサーチクエスチョン
- RQ1チェックポイント読み込みを最適化して、LLMs のマルチ tier GPU サーバー storage 階層を活用することは可能か。
- RQ2LLM 推論のライブマイグレーションは、進行中の推論を妨げずに locality を改善できるか。
- RQ3スケジューラはローカリティ認識のサーバー割り当てを可能にするために、読み込みとマイグレーションの時間を正確に推定できるか。
- RQ4ローカリティ駆動の戦略は、従来のサーバーレス LLM アプローチと比較してレイテンシにどのような影響を与えるか。
主な発見
- ロード最適化済みのチェックポイントとモデルマネージャは、Safetensors および PyTorch に比べて OPT、LLaMA-2、Falcon などのモデルでロード時間を3.6-8.2X短縮する。
- ServerlessLLM は GSM8K および ShareGPT データセットにおける OPT モデル推論の実世界のサーバーレス workloads で 10-200X のレイテンシ改善を達成する。
- トークンベースのマイグレーションと二段階プロセスを用いたライブマイグレーションは、別のサーバーでローカリティ駆動の起動を可能にしつつユーザー体験を維持する。
- ロード時間推定とマイグレーション時間推定を用いたローカリティ認識スケジューラは、起動遅延を最小化するサーバーを選択する。
- マイクロベンチマークは、マルチ tier ストレージを活用して有効なチェックポイント読み込み速度とより高い帯域幅利用を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。