[論文レビュー] ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
この論文は、対象プラットフォーム上の速度/待機時間がCNNの直接的な効率指標であると主張し、実用 guidelines に導かれた ShuffleNet V2 を導入。 prior light-weight models より速度-精度のトレードオフで良好な性能を達成。
Currently, the neural network architecture design is mostly guided by the \emph{indirect} metric of computation complexity, i.e., FLOPs. However, the \emph{direct} metric, e.g., speed, also depends on the other factors such as memory access cost and platform characterics. Thus, this work proposes to evaluate the direct metric on the target platform, beyond only considering FLOPs. Based on a series of controlled experiments, this work derives several practical \emph{guidelines} for efficient network design. Accordingly, a new architecture is presented, called \emph{ShuffleNet V2}. Comprehensive ablation experiments verify that our model is the state-of-the-art in terms of speed and accuracy tradeoff.
研究の動機と目的
- FLOPs を超えたアーキテクチャ設計の動機づけとして、対象ハードウェア上の直接的な速度を検討する。
- 実世界の実行時間性能と相関する実用的な指針を特定する。
- これらの指針に従う効率的なネットワークアーキテクチャ(ShuffleNet V2)を提案する。
- 新しいアーキテクチャがプラットフォームやワークロードを跨いで優れた速度-精度のトレードオフを達成することを示す。
提案手法
- 最も代表的なネットワーク(ShuffleNet v1 と MobileNet v2)を、最適化されたライブラリを用いて GPU と ARM で実行時性能を評価する。
- メモリアクセスコスト(MAC)、グループ畳み込み、ネットワークの断片化、要素ごと演算に焦点を当てた制御可能な実験から指針を導出する。
- 同じ幅のチャンネルを維持しつつ MAC を削減(G2)し、断片化を減らす(G3)チャンネル分割とシャッフルベースのブロックを提案する。
- 過度な断片化と不要な要素ごと演算を避ける ShuffleNet V2 ブロックを構築する(G4)。
- FLOPs レベルとタスク(ImageNet 分類; COCO 検出)を横断して複数のベースラインに対して ShuffleNet V2 をベンチマークする。
- SE モジュールとの適合性やより大きなモデルへの拡張の可能性について論じる。
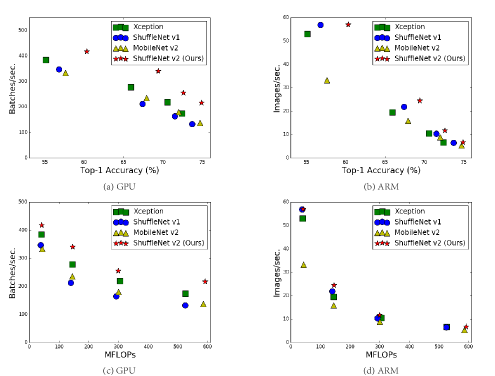
実験結果
リサーチクエスチョン
- RQ1GPU および ARM デバイス上の直接的な速度指標は、軽量 CNN の FLOPs とどのように関連するか?
- RQ2対象プラットフォームで精度を損なうことなく実際の速度を最大化するアーキテクチャ指針は何か?
- RQ3チャンネル分割/シャッフルビルディングブロック設計は、低いメモリアクセスコストと低い断片化で高い精度を提供できるか?
- RQ4標準的な FLOP 予算の下で ShuffleNet V2 は ShuffleNet v1、MobileNet v2、Xception と比較してどう性能を発揮するか?
- RQ5ImageNet 分類に加えて COCO のような物体検出などの下流タスクにも ShuffleNet V2 は有効か?
主な発見
- 直接的な速度はプラットフォーム特性とメモリアクセスに相関し、FLOPs のみでは不十分である。
- チャンネル幅を均等(入力チャネルと出力チャネルが同じ)にすることはメモリアクセスコストを最小化し、速度を向上させる。
- 過度なグループ畳み込みは MAC を増加させ、GPU および ARM CPU を遅くする。中程度のグループ化が望ましい。
- ネットワークの断片化を減らし、過度に小さな断片化した演算を避けることは並列性と速度を向上させ、特に GPU で効果的。
- ボトルネックユニットで特定の要素ごと演算(ReLU、ショートカット)を削除すると、試験設定で大幅な精度低下を招くことなく速度向上を得られる。
- ShuffleNet V2 は、一般に用いられる複雑さ予算において ShuffleNet v1、MobileNet v2、Xception と比較して優れた速度-精度のトレードオフを達成し、COCO の物体検出にも競争力のある性能で一般化する。
![Figure 2 : Run time decomposition on two representative state-of-the-art network architectures, ShuffeNet v1 [ 15 ] (1 $\times$ , $g=3$ ) and MobileNet v2 [ 14 ] (1 $\times$ ).](https://ar5iv.labs.arxiv.org/html/1807.11164/assets/x2.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。