[論文レビュー] SLiC-HF: Sequence Likelihood Calibration with Human Feedback
SLiC-HF は Sequence Likelihood Calibration を適用し、人間の嗜好から学習することで RLHF-PPO の代替としてよりシンプルで効率的、Reddit TL;DR要約およびオフポリシーのフィードバックデータで競争力のある結果を提供します。
Learning from human feedback has been shown to be effective at aligning language models with human preferences. Past work has often relied on Reinforcement Learning from Human Feedback (RLHF), which optimizes the language model using reward scores assigned from a reward model trained on human preference data. In this work we show how the recently introduced Sequence Likelihood Calibration (SLiC), can also be used to effectively learn from human preferences (SLiC-HF). Furthermore, we demonstrate this can be done with human feedback data collected for a different model, similar to off-policy, offline RL data. Automatic and human evaluation experiments on the TL;DR summarization task show that SLiC-HF significantly improves supervised fine-tuning baselines. Furthermore, SLiC-HF presents a competitive alternative to the PPO RLHF implementation used in past work while being much simpler to implement, easier to tune and more computationally efficient in practice.
研究の動機と目的
- 参照要約を超える人間の嗜好にモデルを整合させる動機付け。
- 人間のフィードバックを用いたシーケンスレベルの較正手法として SLiC-HF を導入する。
- 他モデルからのオフポリシーフィードバックデータを SLiC-HF が活用できることを示す。
- Reddit TL;DR要約で SLiC-HF を評価し、RLHF のベースラインと比較する。
提案手法
- 標準データで SFT モデルを微調整し、次に人間の嗜好データを用いて SLiC の較正を適用する。
- ランク正規化損失を用いる: Lcal = max(0, delta - log P_theta(y+|x) + log P_theta(y-|x)).
- モデルが過度にずれないように、ターゲットシーケンス y_ref を用いたクロスエントロピー正則化項を使用する。
- バリアントを探索: SLiC-HF-sample-rank(報酬/ランキングモデルでランク付けされたサンプル候補)と SLiC-HF-direct(HFデータ上で直接較正)
- HFデータでランキングモデルと報酬モデルを訓練して候補デコードを評価し、較正を導く。
- 正則化ターゲットを比較する: SFT データ由来の y_ref とデコードからの最高ランキング候補のどちらか。
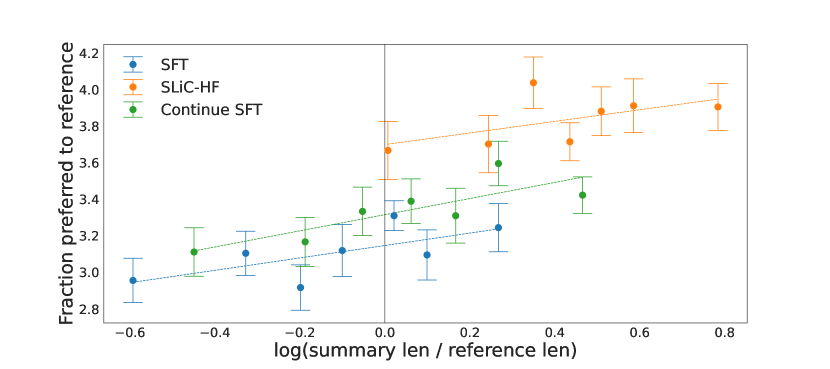
実験結果
リサーチクエスチョン
- RQ1SLiC-HF は人間の嗜好データから学習して、SFT ベースラインを超える要約を改善できるか。
- RQ2性能・トレーニングの単純さ・計算効率の観点から SLiC-HF は RLHF-PPO とどう比較されるか。
- RQ3他モデルのために収集されたデータであるオフポリシーの人間のフィードバックは、SLiC-HF 下で効果的に転送されるか。
- RQ4SLiC-HF の異なるバリアント(sample-rank, direct)と正則化ターゲットが性能に及ぼす影響は何か?
- RQ5ランキングベースのフィードバックモデルは、SLiC の較正を導く際に報酬ベースのモデルとどう比較されるか?
主な発見
- SLiC-HF は人間の評価で Reddit TL;DR における監視付き微調整ベースラインを大幅に上回る。
- ランキングベースのHFモデルは、報酬ベースのHFモデルより高い整合性を達成する(ranking accuracy ~73.2% 対 71.3%)。
- SLiC-HF-sample-rank with ranking は、テストしたバリアントの中で報告された勝率が最も高く(ranker win rate で最大 86.21%)、
- SLiC-HF は RLHF-PPO に対して競争力のある性能を達成し、いくつかのバリアントは人間評価で RLHF-PPO のベースラインを上回る。
- SLiC-HF-direct はシンプルだが出力が長くなりやすく収束が不安定になることがある一方、SLiC-HF-sample-rank は頑健さを保つ。
- モデルサイズを拡大すると SLiC-HF の性能が向上する(例: 11B ランキングモデルと 770M ジェネレーションモデルでの向上)。
- 人間の評価により、複数のベースラインに対して SLiC-HF が最良モデルとして選ばれたのは 73% の回数だった。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。