[論文レビュー] SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
SmolLM2 は 1.7B パラメータの言語モデルで、~11T トークンを用いたマルチステージ、データ中心のアプローチで新データセット(FineMath, Stack-Edu, SmolTalk)を用いて訓練され、同程度のサイズのLMの間で最先端の性能を達成し、データとともにリリースされる。
While large language models have facilitated breakthroughs in many applications of artificial intelligence, their inherent largeness makes them computationally expensive and challenging to deploy in resource-constrained settings. In this paper, we document the development of SmolLM2, a state-of-the-art "small" (1.7 billion parameter) language model (LM). To attain strong performance, we overtrain SmolLM2 on ~11 trillion tokens of data using a multi-stage training process that mixes web text with specialized math, code, and instruction-following data. We additionally introduce new specialized datasets (FineMath, Stack-Edu, and SmolTalk) at stages where we found existing datasets to be problematically small or low-quality. To inform our design decisions, we perform both small-scale ablations as well as a manual refinement process that updates the dataset mixing rates at each stage based on the performance at the previous stage. Ultimately, we demonstrate that SmolLM2 outperforms other recent small LMs including Qwen2.5-1.5B and Llama3.2-1B. To facilitate future research on LM development as well as applications of small LMs, we release both SmolLM2 as well as all of the datasets we prepared in the course of this project.
研究の動機と目的
- 高性能な小規模LMの開発を動機づけ、計算コストを抑えつつ知識・推論・コード・数学の能力を維持する。
- 慎重なデータ選定と段階的訓練が小規模LMの性能を最大化できるかを調査する。
- 専門データセット(数学、コード、指示遵守) がドメイン特化と一般能力へ与える影響を評価する。
- 再現可能な訓練パイプラインと公開データセットを提供し、今後の小規模LM研究を促進する。
提案手法
- 約11Tトークンで1.7BパラメータのTransformer(LLama2ベース)をマルチステージ訓練スケジュールで訓練する。
- 英語ウェブデータのアブレーションを系統的に評価し、データセットの組み合わせを導くとともに、オンザフライのリバランシングを導入する。
- 数学、コード、指示遵守のギャップを埋めるために新しい専門データセットFineMath、Stack-Edu、SmolTalkを作成・統合する。
- 後の段階で高品質ドメイン(数学、コード)のステージごとのデータ混合とアップサンプリングを行い、能力を最大化する。
- チェックポイントとRoPEスケーリングを用いて文脈長を8kトークンへ拡張し長文脈タスクを可能にする。
- 指示チューニング(SmolTalk)と好み学習(DPO)を用いて訓練後の指示遵守バリアントを生成する。
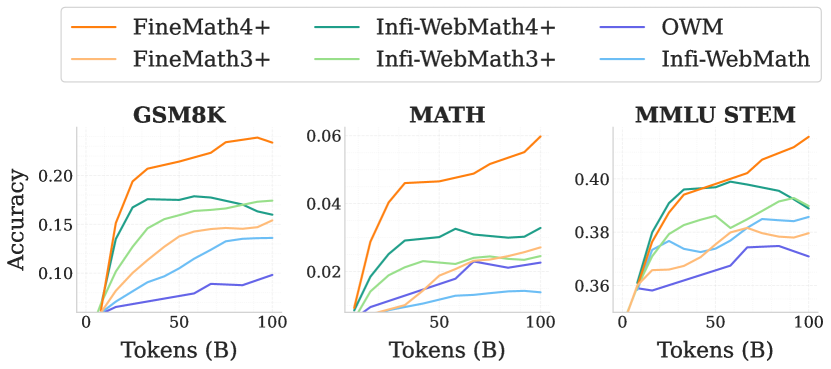
実験結果
リサーチクエスチョン
- RQ1データセット構成と段階的訓練は、ベンチマーク全体で小規模LMの性能にどのような影響を与えるか?
- RQ2専門データ(数学、コード、指示遵守)は小規模LMの推論能力とドメイン特化能力を改善するか?
- RQ3データアップサンプリングと高品質データセットの遅段階導入は全体性能にどのような影響を及ぼすか?
- RQ4データ中心のアプローチで訓練された1.7Bモデルは同程度のサイズのLMの間で最先端の性能を達成できるか?
主な発見
- SmolLM2 (1.7B) は Qwen2.5-1.5B および Llama3.2-1B を 1–2B サイズ範囲のいくつかのベンチマークで上回る。
- 最終ベースの SmolLM2 は一般化能力が強く、MMLU-Pro、TriviaQA、Natural Questions、GSM8K、MATH、HumanEval で友人モデルと比べて顕著な改善。
- 文脈長を2kから8kトークンへ拡張しても性能は堅牢で、退化は観察されなかった。
- 後半で数学とコードを重視した段階的データ混合は、数学とコーディング能力の大幅な改善をもたらす。
- SmolLM2 の指示チューニングバリアント(SmolTalk)と Direct Preference Optimization によるアラインメントは指示遵守性能をさらに高める。
- 本研究は SmolLM2 と準備された全データセット(FineMath、Stack-Edu、SmolTalk)を公開し、今後の研究を支援する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。