[論文レビュー] SPDF: Sparse Pre-training and Dense Fine-tuning for Large Language Models
SPDF は事前学習時の無構造ウェイトのスパース性を用いて FLOP を削減し、ファイントレーニング時に密にして容量を回復させ、下流の性能を維持します。
The pre-training and fine-tuning paradigm has contributed to a number of breakthroughs in Natural Language Processing (NLP). Instead of directly training on a downstream task, language models are first pre-trained on large datasets with cross-domain knowledge (e.g., Pile, MassiveText, etc.) and then fine-tuned on task-specific data (e.g., natural language generation, text summarization, etc.). Scaling the model and dataset size has helped improve the performance of LLMs, but unfortunately, this also lead to highly prohibitive computational costs. Pre-training LLMs often require orders of magnitude more FLOPs than fine-tuning and the model capacity often remains the same between the two phases. To achieve training efficiency w.r.t training FLOPs, we propose to decouple the model capacity between the two phases and introduce Sparse Pre-training and Dense Fine-tuning (SPDF). In this work, we show the benefits of using unstructured weight sparsity to train only a subset of weights during pre-training (Sparse Pre-training) and then recover the representational capacity by allowing the zeroed weights to learn (Dense Fine-tuning). We demonstrate that we can induce up to 75% sparsity into a 1.3B parameter GPT-3 XL model resulting in a 2.5x reduction in pre-training FLOPs, without a significant loss in accuracy on the downstream tasks relative to the dense baseline. By rigorously evaluating multiple downstream tasks, we also establish a relationship between sparsity, task complexity and dataset size. Our work presents a promising direction to train large GPT models at a fraction of the training FLOPs using weight sparsity, while retaining the benefits of pre-trained textual representations for downstream tasks.
研究の動機と目的
- 事前学習の計算コストを低減しつつ下流の精度を犠牲にしない動機付け。
- Sparse Pre-training and Dense Fine-tuning (SPDF) を二段階のトレーニングフレームワークとして提案。
- 事前学習中の高いスパース性(最大75%)が FLOP を削減しつつ、密にファインチューニングした後の性能を維持できることを実証。
- スパース性のレベルがタスク難易度、データセット規模、モデルスケールにどう関連するかを調査。
- 事前学習モデルとファインチューニングモデル間のパラメータサブスペースの移動を分析。
提案手法
- 事前学習前に密な GPT 系モデルへ一様な静的な非構造スパース性を適用。
- 固定スパースマスクを用いたマスク付き自己回帰目的を最小化するよう、大規模テキストコーパス上でスパースモデルを事前学習。
- 以前にゼロにされていたすべての重みを復活させ(ゼロ初期化)、下流タスクで密にファインチューニングへ移行。
- 自然言語生成とテキスト要約タスクを横断して下流の転移を評価。
- FLOP を測定し、密学習と比較して効率向上を定量化。
実験結果
リサーチクエスチョン
- RQ1事前学習中の高いスパース性(50-75%)は、密なファインチューニング後の下流の性能を維持できるか?
- RQ2SPDF のスパース性はデータセットサイズとタスク難易度とどう相互作用するか?
- RQ3より大きなモデルサイズ(例:GPT-3 XL)は下流劣化を抑えつつ高いスパース性を許容できるか?
- RQ4SPDF によるモデルスケールとタスク間で達成可能な FLOP 削減はどれくらいか?
- RQ5SPDF の下で事前学習とファインチューニングのパラメータサブスペースはどう関係するか?
主な発見
| モデル | 事前学習スパース性 | E2E FLOPs(×10^18) | WebNLG FLOPs(×10^18) | DART FLOPs(×10^18) | キュレーションコーパス FLOPs(×10^18) |
|---|---|---|---|---|---|
| GPT-2 Small | 0% | 2.48 (1.00x) | 2.48 (1.00x) | 2.45 (1.00x) | 2.44 (1.00x) |
| GPT-2 Small | 50% | 1.84 (1.34x) | 1.82 (1.35x) | 1.84 (1.34x) | 1.81 (1.35x) |
| GPT-2 Small | 75% | 1.52 (1.64x) | 1.49 (1.65x) | 1.52 (1.64x) | 1.48 (1.65x) |
| GPT-3 XL | 0% | 236.62 (1.00x) | 236.62 (1.00x) | 236.33 (1.00x) | 236.32 (1.00x) |
| GPT-3 XL | 50% | 142.40 (1.66x) | 142.10 (1.66x) | 142.01 (1.66x) | 142.40 (1.66x) |
| GPT-3 XL | 75% | 95.29 (2.48x) | 94.98 (2.49x) | 95.29 (2.48x) | 94.90 (2.49x) |
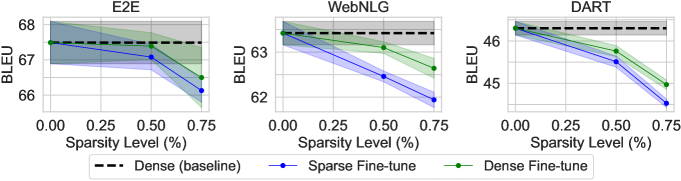
- 事前学習で GPT-2 Small および GPT-3 XL を最大75%のスパース性で学習させても、NLG タスクの BLEU/ペ perplexity の低下は抑えられ、モデルが大きいほどスパース性に対する耐性が高い。
- スパースな事前学習後の密なファインチューニングは、スパースなファインチューニングだけの場合と比較して性能低下を緩和。
- SPDF はモデルサイズに応じて FLOP を大幅に削減し、GPT-2 Small で約1.65x、GPT-3 XL で約2.48x〜2.49x の総 FLOP 削減を実現(事前学習で75%スパースの場合)。
- 下流タスクの難易度はスパース性耐性と相関し、キュレーション系コーパス(要約)は高いスパース性に対してより敏感である、E2E、WebNLG、DART より。
- 大規模モデルは事前学習とファインチューニングのパラメータサブスペース間のコサイン距離が小さく、ファインチューニング時の適応が少なくて済むことを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。