[論文レビュー] STaR-GATE: Teaching Language Models to Ask Clarifying Questions
STaR-GATE は、ユーザーの嗜好を引き出すためのより明確な質問をするよう言語モデルを微調整します。2回の反復の後、初期モデルに対する比較で回答が72%の勝利率を達成します。
When prompting language models to complete a task, users often leave important aspects unsaid. While asking questions could resolve this ambiguity (GATE; Li et al., 2023), models often struggle to ask good questions. We explore a language model's ability to self-improve (STaR; Zelikman et al., 2022) by rewarding the model for generating useful questions-a simple method we dub STaR-GATE. We generate a synthetic dataset of 25,500 unique persona-task prompts to simulate conversations between a pretrained language model-the Questioner-and a Roleplayer whose preferences are unknown to the Questioner. By asking questions, the Questioner elicits preferences from the Roleplayer. The Questioner is iteratively finetuned on questions that increase the probability of high-quality responses to the task, which are generated by an Oracle with access to the Roleplayer's latent preferences. After two iterations of self-improvement, the Questioner asks better questions, allowing it to generate responses that are preferred over responses from the initial model on 72% of tasks. Our results indicate that teaching a language model to ask better questions leads to better personalized responses.
研究の動機と目的
- ユーザーとLMの対話におけるタスクの曖昧さを動機づけ、嗜好抽出の必要性を定義する。
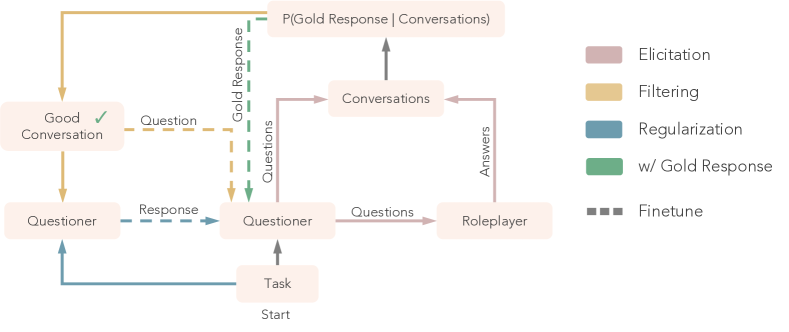
- 嗜好抽出と自己対話ループを組み合わせた反復的な自己改善フレームワークとして STaR-GATE を導入する。
- 学習を支援するため、ペルソナ-タスクのプロンプトと金標準応答の合成データセットを作成する。
- 抽出された質問と自己生成された応答で微調整することが、下流の応答品質を改善することを示す。
提案手法
- ペルソナアクセスを持つ Oracle を使用して、金標準応答を含む25,500件のペルソナ-タスクプロンプトの合成データセットを生成する。
- 対象質問を通じてユーザーの嗜好を引き出すよう、Questioner–Roleplayer の対話をシミュレートする。
- Questioner のプロンプトと Roleplayer の嗜好の下での金標準応答の対数確率に基づく報酬を定義する。
- 最良の対話と対応するモデル応答を用いて Questioner を微調整する(Expert Iteration スタイル)。
- トレーニング中に前回の反復の応答を含めて分布シフトを防ぐ正則化を行う。

実験結果
リサーチクエスチョン
- RQ1ユーザーの嗜好が不明な場合に、情報理論的な質問を学習してタスク性能を改善できる言語モデルは存在するか。
- RQ2嗜好抽出を伴う反復的な自己改善は、金標準応答の尤度と実践的なタスク性能を改善するか。
- RQ3自己生成された応答の含有と正則化は、学習の安定性と出力の現実性にどう影響するか。
- RQ4トレーニングペルソナ以外のさまざまな Roleplayer に対しても、利得は一般化するか。
- RQ5正則化の必須性や質問と応答の学習の違いについて、どのようなアブレーションが明らかにするか。
主な発見
- 質問に焦点を当てた微調整は、反復を通じて金標準応答の対数確率を高める。
- STaR-GATE は2回の反復後、初期モデルに対して72%の勝率を達成する。
- このアプローチは、トレーニングペルソナを超えた Roleplayer に対して一般化する(部分的な頑健性を実証)。
- 自己生成された応答を用いた正則化は、応答方法を忘れるのを防ぎ、幻覚を避けるために重要である。
- アブレーションは、質問のみでの学習が性能を低下させる一方、金標準応答での学習は現実味のない出力を招くことを示す。
- 応答正則化を行った STaR-GATE は、質問のみ、または金標準応答のみを学習したバージョンよりも優れている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。