[論文レビュー] StarCoder: may the source be with you!
StarCoderBase と StarCoder は The Stack で訓練され、8K コンテキストを備えたオープンアクセスの 15.5B Code LLM で、優れたオープンモデル性能を発揮し、OpenAI の code-cushman-001 に匹敵するまたは上回る、さらに公開リリースのための安全性と帰属付けツールを提供します。
The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
研究の動機と目的
- StarCoderBase および StarCoder を含む広範な言語サポートを持つオープンアクセスのコード LLM を開発する。
- The Stack の緩いライセンスのデータを訓練に用い、データを慎重に選別する。
- 公開・非公開コード LLMs と比較した包括的評価を実施し、安全性ツールを評価する。
- 帰属追跡の提供、PII のマスキングの改善、利用しやすいライセンスを通じて責任ある展開を実現する。
- 文書を伴う商用利用可能なオープンライセンスの下でモデルを公表する。
提案手法
- 15.5B パラメータのモデルを 8K トークンのコンテキストと Fill-in-the-Middle のインフィリングで使用します。
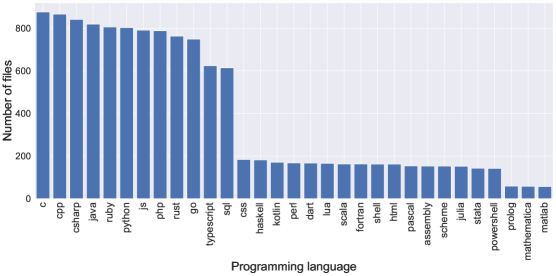
- StarCoderBase は The Stack から 1 兆トークンを、80 を超える言語、GitHub の issues、コミット、ノートブックを横断して訓練しています。
- StarCoder は 追加の 35B Python トークンで微調整された派生モデルです。
- Multi-Query-Attention による高速大バッチ推論を実装します。
- データ選別フィルターには言語選択、XML/HTML/JSON/YAML の処理、Jupyter ノートブックの処理が含まれます。
- コードデータには重複排除パイプライン(MinHashes および LSH)を適用し、コミットのデータ量はサンプリングします。
- PII のマスキングを専用データセットと StarEncoder モデルを用いて強化し、トレーニングデータのトレース用に帰属ツールを VSCode デモに統合します。
実験結果
リサーチクエスチョン
- RQ1StarCoderBase および StarCoder は多言語サポートの面でオープン Code LLMs とどう比較されるか。
- RQ2StarCoderBase および StarCoder は評価ベンチマークで OpenAI code-cushman-001 に匹敵するまたは上回るか。
- RQ3Python での微調整が StarCoder を他の Python 対応モデルより優位にし、かつ他言語の性能を維持できるか。
- RQ4オープンアクセス公開を安全で透明にするための帰属ツールと改善された PII マスキングで実現できるか。
主な発見
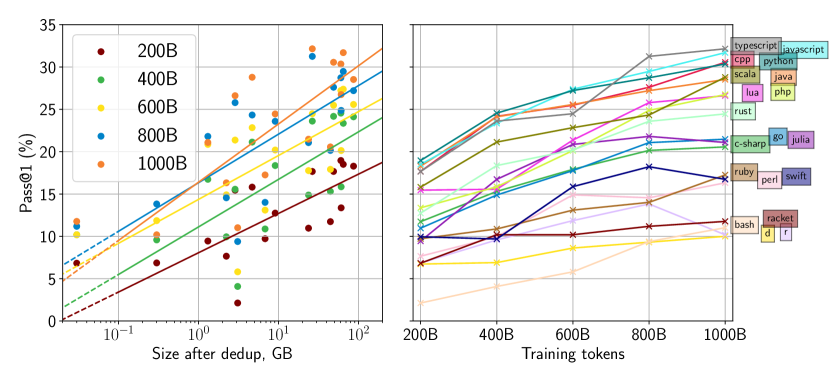
- StarCoderBase は複数のプログラミング言語をサポートする全てのオープン LLM を上回る。
- StarCoderBase は OpenAI の code-cushman-001 モデルと同等かそれを上回る。
- Python での微調整を行うと StarCoder は既存の Python 対応 LLM より大きく優位になる。
- StarCoder は Python で微調整された全てのモデルを上回り、他の言語の性能を維持する。
- リリースには OpenRAIL-M ライセンス、帰属追跡ツール、訓練データ追跡用の訓練済み StarEncoder を備えた改善された PII 赤action パイプラインが含まれる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。