[論文レビュー] The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
FineWeb は 96 の Common Crawl スナップショットに由来する 15兆トークンのオープン事前学習データセットであり、教育用サブセット FineWeb-Edu は 1.3兆トークンである。著者らはエンドツーエンドのキュレーションとアブレーション研究を文書化し、オープンデータでの堅牢な性能を達成している。
The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset. However, the pretraining datasets for state-of-the-art open LLMs like Llama 3 and Mixtral are not publicly available and very little is known about how they were created. In this work, we introduce FineWeb, a 15-trillion token dataset derived from 96 Common Crawl snapshots that produces better-performing LLMs than other open pretraining datasets. To advance the understanding of how best to curate high-quality pretraining datasets, we carefully document and ablate all of the design choices used in FineWeb, including in-depth investigations of deduplication and filtering strategies. In addition, we introduce FineWeb-Edu, a 1.3-trillion token collection of educational text filtered from FineWeb. LLMs pretrained on FineWeb-Edu exhibit dramatically better performance on knowledge- and reasoning-intensive benchmarks like MMLU and ARC. Along with our datasets, we publicly release our data curation codebase and all of the models trained during our ablation experiments.
研究の動機と目的
- 公開された高品質の事前学習データがオープンLLMにとって必要である理由を動機づける。
- 透明なキュレーションパイプラインを備えた大規模ウェブテキストデータセット(FineWeb)を開発・公開する。
- ダウンストリームの性能への影響を理解するため、フィルタリング、重複排除、テキスト抽出の選択を体系的にアブレーションして文書化する。
- 知識・推論集約コンテンツをフィルタリングするための合成注釈を用いた教育用サブセット(FineWeb-Edu)を作成する。
- 再現性とさらなる研究を支援するツール(datatrove)と訓練済みモデルを提供する。
提案手法
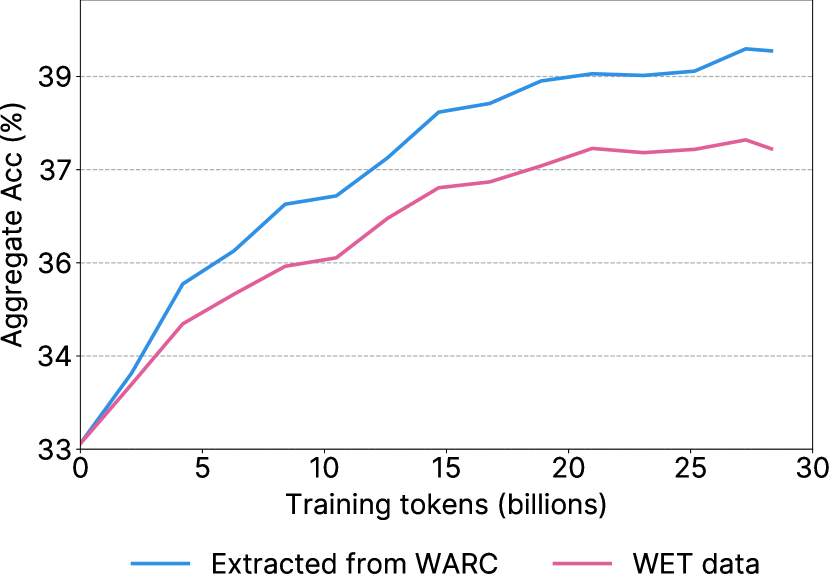
- WARC ファイルからのテキスト抽出を Trafilatura ライブラリで行い、WET ベースの抽出より高品質なテキストを取得する。
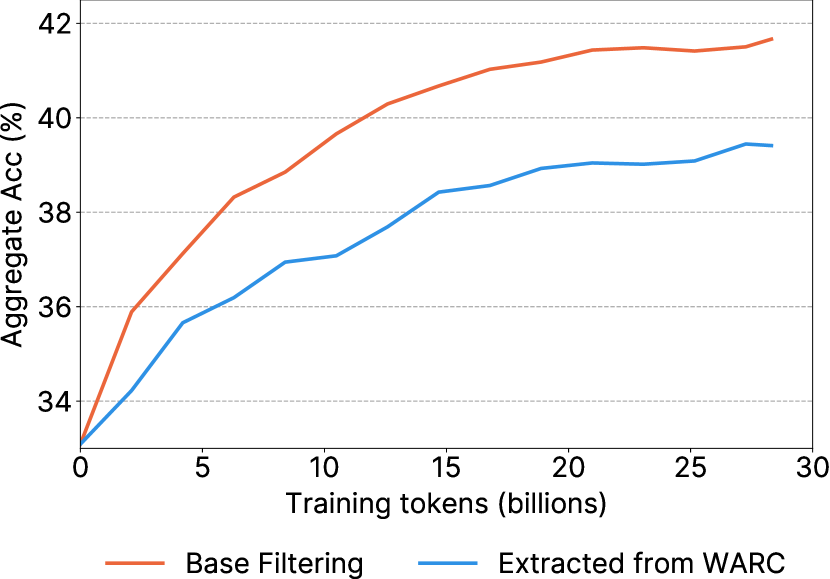
- URL ブロックリスト、英語用 fastText 言語フィルタリング、品質/繰り返しフィルタを組み込んだベースフィルタリングパイプラインを適用する(MassiveText に触発)。
- 14 バケットにわたって 5-grams と 112 hash 関数を用いた各クロールごとの MinHash 重複排除を実施して重複を削減する。
- ベンチマーク性能を向上させるために、過度なトークン損失を招かずに選択した C4 風ヒューリスティックフィルタを用いてフィルタリングを補強する。
- 高品質データと低品質データの分布を分析して 3 つのフィルタを選択し、総合スコアを向上させる追加のヒューリスティックフィルタを開発する。
- 再現性を可能にするためにデータセット、datatrove 処理ライブラリ、アブレートされたモデルを公開する。
実験結果
リサーチクエスチョン
- RQ1テキスト抽出、フィルタリング、重複排除の決定はオープンデータセット上の下流の LLM パフォーマンスにどう影響するか?
- RQ2各クロールごとの重複排除とターゲットを絞ったフィルタは、グローバルな重複排除よりモデル品質の向上に寄与するか?
- RQ3C4 風フィルタとカスタムヒューリスティクスを導入すると、ベースフィルタリングだけの場合より顕著な向上が得られるか?
- RQ4特にキュレーションされた教育コンテンツサブセット(FineWeb-Edu)は、知識・推論集約のベンチマークを改善するか?
主な発見
- WARC ベースの Trafilatura によるテキスト抽出は WET ベースの抽出より性能が高い。
- ベースフィルタリングは生データに対して大幅な向上を提供する。
- 各クロール個別 MinHash 重複排除は、グローバル重複排除より平均パフォーマンスを改善する。
- All-C4 型フィルタは、最良の単一 C4 フィルタよりも優れており、トークンをより少なく失いながらも優位に立つ。
- カスタムヒューリスティックフィルタは総合ベンチマークスコアをさらに改善し、データ損失が少なくて済む場合には C4 のみを上回ることがある。
- FineWeb-Edu は MMLU や ARC のような教育系ベンチマークで優れた性能を、トークン数を抑えた状態で達成する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。