[論文レビュー] The Good, The Bad, and The Greedy: Evaluation of LLMs Should Not Ignore Non-Determinism
本論文は、多様なベンチマークとモデルにわたって貪欲デコードとサンプリングを比較することにより、LLM生成における非決定性を調査し、貪欲法が多くの場合優位である一方、顕著な例外があり、アラインメント、スケーリング、best-of-N戦略の影響を強調する。
Current evaluations of large language models (LLMs) often overlook non-determinism, typically focusing on a single output per example. This limits our understanding of LLM performance variability in real-world applications. Our study addresses this issue by exploring key questions about the performance differences between greedy decoding and sampling, identifying benchmarks' consistency regarding non-determinism, and examining unique model behaviors. Through extensive experiments, we observe that greedy decoding generally outperforms sampling methods for most evaluated tasks. We also observe consistent performance across different LLM sizes and alignment methods, noting that alignment can reduce sampling variance. Moreover, our best-of-N sampling approach demonstrates that smaller LLMs can match or surpass larger models such as GPT-4-Turbo, highlighting the untapped potential of smaller LLMs. This research shows the importance of considering non-determinism in LLM evaluations and provides insights for future LLM development and evaluation.
研究の動機と目的
- 単一の決定論的結果ではなく、LLM出力の非決定性を評価する必要性を動機づける。
- 多様なベンチマークにおいて、貪欲デコードがサンプリングより優れている場合とそうでない場合を特徴づける。
- モデルサイズやアラインメント手法間で非決定性の効果の一貫性を評価する。
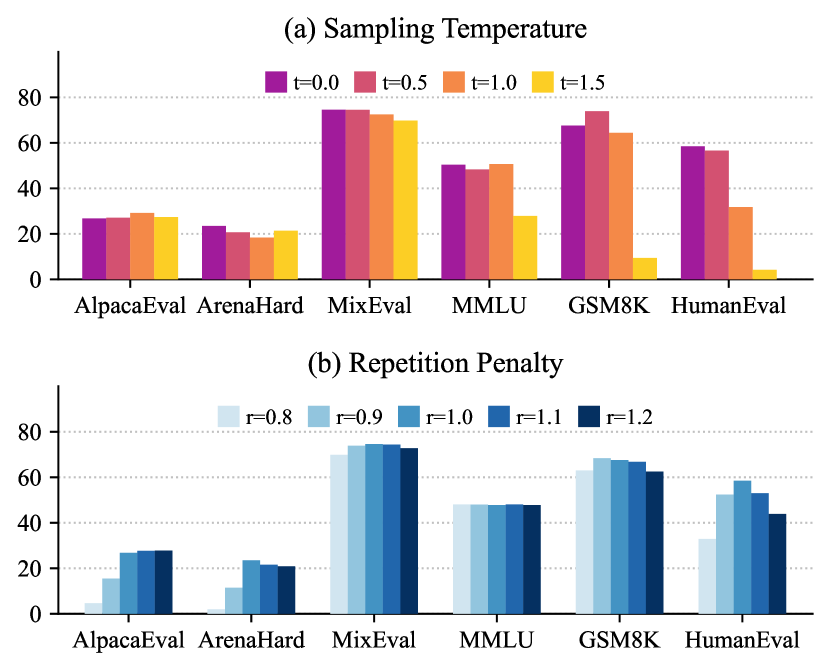
- スケーリング、アラインメント、温度、反復ペナルティなど、非決定的な生成に影響を与える要因を探る。
- 小規模なLLMの能力を引き出すためのbest-of-Nサンプリングの可能性を示す。
提案手法
- AlpacaEval 2, Arena-Hard, WildBench v2, MixEval, MMLU-Redux, GSM8K, and HumanEval を含む7つのベンチマークで、greedy decodingとnucleus samplingを比較する。
- 複数のオープンウェイトLLMと独自のGPT-4-Turboベースラインを評価する。
- ほとんどのベンチマークで16回の完了をサンプリングし、MMLU-Reduxで32、GSM8KとHumanEvalで128。
- スケーリング、アラインメント手法(例:DPO、KTO、SimPO)、温度、反復ペナルティの影響を調査する。
- 報酬モデルを用いたbest-of-Nサンプリングで上位応答をランク付け・選択し、oracle upper boundsと比較する。
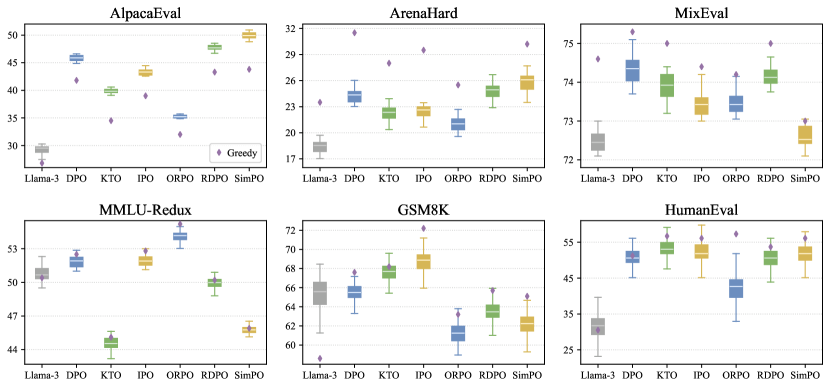
実験結果
リサーチクエスチョン
- RQ1Q1: ベンチマークとモデル間で、greedy decodingとsamplingの性能ギャップはどのように異なるか。
- RQ2Q2: greedy decodingはいつsamplingより優れており、いつそうでないのか、そしてその理由は何か。
- RQ3Q3: 非決定性に関してどのベンチマークが最も/最も一致しないのか。
- RQ4Q4: どのモデルがタスク横断で特徴的な非決定的パターンを示すか。
主な発見
- Greedy decoding generally outperforms sampling on most benchmarks, though rankings can change by configuration.
- AlpacaEval is an exception where sampling shows higher win rate.
- Benchmarks with constrained output spaces (e.g., MixEval, MMLU) show more stability, while math and coding tasks (GSM8K, HumanEval) are more affected by sampling variance.
- Results are consistent across different model sizes and families; alignment methods can reduce sampling variance in many tasks.
- Best-of-N sampling with reward models can let smaller LLMs match or exceed GPT-4-Turbo on several tasks, with oracle best-of-N illustrating upper-bound potential.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。