[論文レビュー] Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Time-LLMは入力時系列をテキストプロトタイプとして再プログラムし、Prompt-as-Prefixを用いた凍結LLMで予測を行い、バックボーンの微調整無しで、少数ショット、ゼロショット、及び全体的に最先端の性能を達成します。
Time series forecasting holds significant importance in many real-world dynamic systems and has been extensively studied. Unlike natural language process (NLP) and computer vision (CV), where a single large model can tackle multiple tasks, models for time series forecasting are often specialized, necessitating distinct designs for different tasks and applications. While pre-trained foundation models have made impressive strides in NLP and CV, their development in time series domains has been constrained by data sparsity. Recent studies have revealed that large language models (LLMs) possess robust pattern recognition and reasoning abilities over complex sequences of tokens. However, the challenge remains in effectively aligning the modalities of time series data and natural language to leverage these capabilities. In this work, we present Time-LLM, a reprogramming framework to repurpose LLMs for general time series forecasting with the backbone language models kept intact. We begin by reprogramming the input time series with text prototypes before feeding it into the frozen LLM to align the two modalities. To augment the LLM's ability to reason with time series data, we propose Prompt-as-Prefix (PaP), which enriches the input context and directs the transformation of reprogrammed input patches. The transformed time series patches from the LLM are finally projected to obtain the forecasts. Our comprehensive evaluations demonstrate that Time-LLM is a powerful time series learner that outperforms state-of-the-art, specialized forecasting models. Moreover, Time-LLM excels in both few-shot and zero-shot learning scenarios.
研究の動機と目的
- 一般化可能でデータ効率の高いLLM能力が恩恵を受ける可能性のある領域として時系列予測を動機づける。
- Time-LLMを提案し、時系列入力をテキストプロトタイプへ再プログラムし、プロンプトでLLM推論を導く。
- Time-LLMがベンチマークや少数ショット/ゼロショット設定で最先端の専門的予測モデルを上回ることを実証する。
提案手法
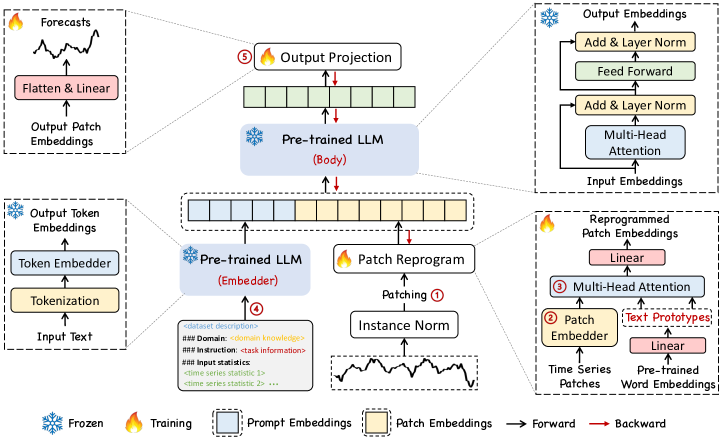
- パッチベースの入力変換:多変量時系列を正規化、パッチ化、埋め込みを行い、パッチを分割して埋め込みを作成する。
- パッチ再プログラミング:小さなテキストプロトタイプ語彙とクロスアテンションを用いてパッチ埋め込みをLLMの入力空間へマッピングし、バックボーンを更新せずに実行する(E, E′, W^Q, W^K, W^V)。
- Prompt-as-Prefix(PaP):タスク指示、データセットの文脈、入力統計をプレフィックスとして追加し、LLMの推論を豊かにしパッチ変換を誘導する。
- 出力投影:再プログラムされたパッチを凍結LLMに通し、得られた表現を平坦化して線形投影し予測を得る。
- バックボーン:事前学習済みのLLMを凍結したまま(例:Llama-7B)にし、軽量な入力変換および出力投影モジュールのみ訓練する。
- 最適化:予測と真値との平均二乗誤差を最小化し、必要に応じて量子化などの効率化手法を統合する。
実験結果
リサーチクエスチョン
- RQ1Time-LLMはバックボーンのLLMをファインチューニングせずに時系列を予測できるか?
- RQ2時系列入力をテキストプロトタイプへ再プログラミングすることが、プロンプトと組み合わせて予測の推論を強化するか?
- RQ3Time-LLMの長期・短期・少数ショット・ゼロショット設定での性能は、最先端の専門予測モデルと比較してどうか?
主な発見
| データセット | Time-LLM_MSE | Time-LLM_MAE |
|---|---|---|
| ETTh1 | 0.408 | 0.423 |
| ETTh2 | 0.334 | 0.383 |
| ETTm1 | 0.329 | 0.372 |
| ETTm2 | 0.251 | 0.313 |
| Weather | 0.225 | 0.257 |
| ECL | 0.158 | 0.252 |
| Traffic | 0.388 | 0.264 |
| ILI | 1.435 | 0.801 |
- Time-LLMは、特に少数ショットとゼロショットのシナリオで、ベンチマーク全体で最先端の予測手法を一貫して上回る。
- 時系列をテキストプロトタイプとして再プログラムし、Prompt-as-Prefixと組み合わせることで、強力なクロスモダリティ整合性を実現し予測精度を向上させる。
- Time-LLMは長期予測でGPT4TSやTimesNetに大きな利得をもたらし、短期データではタスク別トランスフォーマーと同等かそれ以上の競争力を持ち続ける。
- アブレーション研究により、パッチ再プログラミング、Prompt-as-Prefix、入力統計が性能に大きく寄与し、特に入力統計が顕著な影響を与えることが示される。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。