[論文レビュー] Tokenization counts: the impact of tokenization on arithmetic in frontier LLMs
この論文は、数字トークン化の方向性(左から右 L2R 対 右から左 R2L)が GPT-3.5 および GPT-4の算術性能に著しく影響することを示しており、R2L が一般により良い結果をもたらす。モデルはトークン化を変換して性能を回復でき、効果はより大きなモデルでも持続する。
Tokenization, the division of input text into input tokens, is an often overlooked aspect of the large language model (LLM) pipeline and could be the source of useful or harmful inductive biases. Historically, LLMs have relied on byte pair encoding, without care to specific input domains. With the increased use of LLMs for reasoning, various number-specific tokenization schemes have been adopted, with popular models like LLaMa and PaLM opting for single-digit tokenization while GPT-3.5 and GPT-4 have separate tokens for each 1-, 2-, and 3-digit numbers. In this work, we study the effect this choice has on numerical reasoning through the use of arithmetic tasks. We consider left-to-right and right-to-left tokenization for GPT-3.5 and -4, finding that right-to-left tokenization (enforced by comma separating numbers at inference time) leads to largely improved performance. Furthermore, we find that model errors when using standard left-to-right tokenization follow stereotyped error patterns, suggesting that model computations are systematic rather than approximate. We show that the model is able to convert between tokenizations easily, thus allowing chain-of-thought-inspired approaches to recover performance on left-to-right tokenized inputs. We also find the gap between tokenization directions decreases when models are scaled, possibly indicating that larger models are better able to override this tokenization-dependent inductive bias. In summary, our work performs the first study of how number tokenization choices lead to differences in model performance on arithmetic tasks, accompanied by a thorough analysis of error patterns. We hope this work inspires practitioners to more carefully ablate number tokenization-related choices when working towards general models of numerical reasoning.
研究の動機と目的
- 先端となる LLM における数値推論における潜在的な帰納的バイアスとしての数値トークン化を慎重に検討する動機付け。
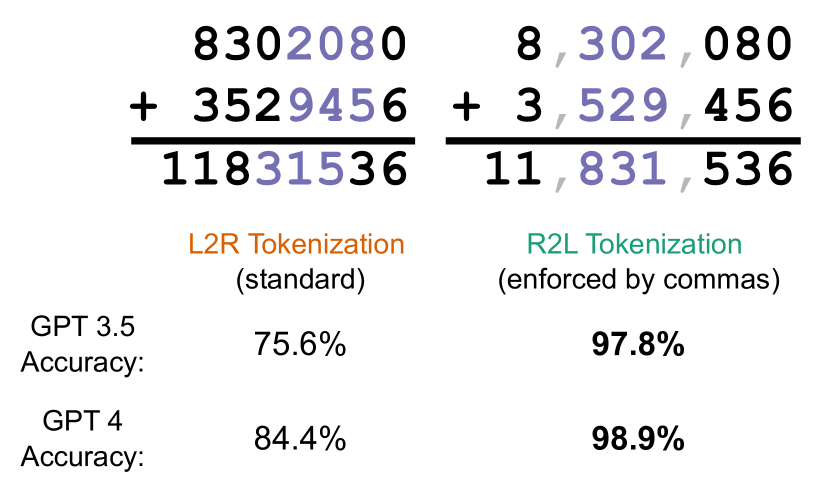
- GPT-3.5 および GPT-4 における左から右(L2R)および右から左(R2L)トークン化による算術性能の比較。
- トークン化が推論プロセスに与える影響を理解するための誤りパターンの分析。
- トークン化関連のバイアスをモデルのスケールが緩和するかを評価する。
提案手法
- 実験設定は OpenAI Chat Completions API を用いて、7〜9 桁の被加算数を用いた少数ショットの加算タスクをテストする。
- 入力のセグメンテーションを変更するため、3桁ごとに区切り文字(カンマなど)を挿入して R2L トークン化を強制する。
- 1-shot, 2-shot, 4-shot, 8-shot プロンプトおよびモデルバージョン(GPT-3.5、GPT-4 および派生版)間で正確さを測定する。
- フォーマット前提と "thinking tokens" を制御するためのアブレーションを実施し、代替の区切り文字やトークン化方向を出力と分離するプロンプトを含める。
- 誤りパターンを分析して、L2R トークン化が機能不全となる時期(例:長さの不一致ケース)と誤りの性質(桁レベルの誤り)を特徴づける。
実験結果
リサーチクエスチョン
- RQ1トークン化方向(L2R vs R2L)が先端的な LLM の算術精度にどのように影響するか?
- RQ2トークン化による効果はモデルバージョンやより大きなモデルにおいても持続するか?
- RQ3異なるトークン化方式の下でどのような誤りパターンが現れ、それが体系的な計算か近似的な一致を示唆するか?
- RQ4トークン化間で入力を変換するようプロンプトを促すことで性能差を緩和できるか?
- RQ5観測された効果はトークン境界によるものか、それともより広い訓練データの事前知識によるものか?
主な発見
- R2L トークン化は L2R よりも GPT-3.5 および GPT-4 の算術精度を大幅に高める(例:最大で 20% の精度向上)。
- R2L と L2R の精度差はショット数が増えると拡大するが飽和し、8-shot 試行全体で R2L の堅牢な利得を示す。
- 長さ不一致ケース(答えの方が被加算数より長い場合)は L2R の性能を不均衡に悪化させ、入力と出力の間のトークン化による不整合を露呈する。
- 長さ不一致の状況では L2R が桁4の高度に型にはまった誤りを生み出し、系統的な処理パターンを示唆する。
- モデルは L2R 入力を R2L 出力に変換して精度を回復でき、少数ショットのプロンプトで好ましいトークン化で問題を繰り返させることが可能。
- トークン化依存の効果は GPT-4 系を含む新しいモデルにも一般的に及ぶが、その大きさはモデルのバージョンと設定により異なる。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。