[論文レビュー] TransXNet: Learning Both Global and Local Dynamics with a Dual Dynamic Token Mixer for Visual Recognition
Dual Dynamic Token Mixer (D-Mixer) を導入し、視覚バックボーンのグローバル情報と局所情報を共同で捉え、分類・検出・分割の各タスクにおいて高い精度と効率を発揮する TransXNet を提案。
Recent studies have integrated convolutions into transformers to introduce inductive bias and improve generalization performance. However, the static nature of conventional convolution prevents it from dynamically adapting to input variations, resulting in a representation discrepancy between convolution and self-attention as the latter computes attention maps dynamically. Furthermore, when stacking token mixers that consist of convolution and self-attention to form a deep network, the static nature of convolution hinders the fusion of features previously generated by self-attention into convolution kernels. These two limitations result in a sub-optimal representation capacity of the entire network. To find a solution, we propose a lightweight Dual Dynamic Token Mixer (D-Mixer) to simultaneously learn global and local dynamics via computing input-dependent global and local aggregation weights. D-Mixer works by applying an efficient global attention module and an input-dependent depthwise convolution separately on evenly split feature segments, endowing the network with strong inductive bias and an enlarged receptive field. We use D-Mixer as the basic building block to design TransXNet, a novel hybrid CNN-Transformer vision backbone network that delivers compelling performance. In the ImageNet-1K classification, TransXNet-T surpasses Swin-T by 0.3% in top-1 accuracy while requiring less than half of the computational cost. Furthermore, TransXNet-S and TransXNet-B exhibit excellent model scalability, achieving top-1 accuracy of 83.8% and 84.6% respectively, with reasonable computational costs. Additionally, our proposed network architecture demonstrates strong generalization capabilities in various dense prediction tasks, outperforming other state-of-the-art networks while having lower computational costs. Code is publicly available at https://github.com/LMMMEng/TransXNet.
研究の動機と目的
- ハイブリッド CNN-Transformer バックボーンを動機づけ、入力依存ダイナミクスを導入して静的畳み込みのボトルネックを克服する。
- グローバル情報と局所情報を統合して有効受容野(ERF)を広げる軽量なトークンミキサーを設計する。
- D-Mixer と MS-FFN を用いて視覚認識タスク向けの階層的バックボーン(TransXNet)を構築する。
- TransXNet が分類・検出・分割で、計算コストを抑えつつ最先端または競合レベルの結果を達成することを示す。
- コンポーネントの妥当性と一般化を検証するアブレーションと転移性分析を提供する。
提案手法
- Dual Dynamic Token Mixer (D-Mixer) を提案し、特徴を二つのチャネル半分に分割して OSRA(グローバル)と IDConv(入力依存の局所)で処理し、結果を結合する。
- 入力依存の Depthwise Convolution (IDConv) を導入し、入力適応型で空間的に変化する Depthwise カーネルを生成する。
- Overlapping Spatial Reduction Attention (OSRA) を導入し、オーバーラップするパッチでグローバル文脈を捕捉する。
- Squeezed Token Enhancer (STE) を追加し、トークン混合後のチャネル情報を効率的に融合する。
- Multi-scale Feed-forward Network (MS-FFN) を、サイズ {3,5,7} の並列 Depthwise 畳み込みを用いて多スケールのトークン集約を行う。
- DPE レイヤリング、D-Mixer ブロック、MS-FFN ブロックを備えた四段階の階層アーキテクチャを組み込み、TransXNet バリアント(T、S、B)を形成する。
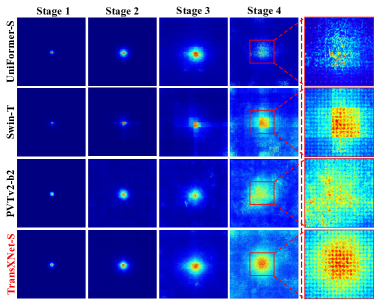
実験結果
リサーチクエスチョン
- RQ1D-Mixer による入力依存ダイナミクスは、ハイブリッド CNN-Transformer バックボーンにおける表現能力と一般化を静的畳み込みと比べて向上させるか。
- RQ2ステージ間でのグローバルアテンションと動的局所畳み込みを組み合わせることで受容野を拡大し、視覚タスクの性能を向上させるか。
- RQ3D-Mixer の各要素(OSRA、IDConv、STE)と MS-FFN が ImageNet-1K および下流タスク(COCO、ADE20K)にどのように寄与するか。
- RQ4TransXNet バリアント(T、S、B)の精度とコストのトレードオフは、現代の SOTA バックボーンと比較してどうか。
- RQ5特化した実装を用いずに、オブジェクト検出、インスタンス/セマンティック分割への利得は効果的に転移するか。
主な発見
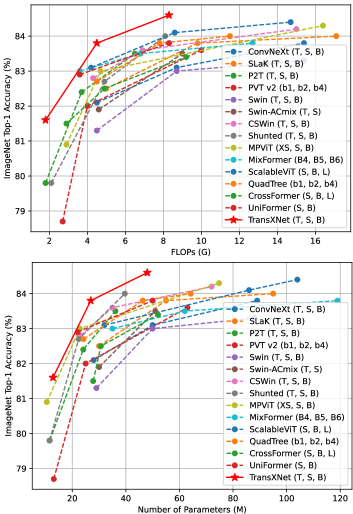
- TransXNet-T は ImageNet-1K で top-1 accuracy 81.6% を達成、1.8G FLOPs、12.8M パラメータで、Swin-T を 0.3% 上回り、コストは半分未満を実現。
- TransXNet-S は ImageNet-1K で top-1 83.8% を達成、競合する FLOPs とパラメータを維持しつつ InternImage-T や複数のハイブリッドモデルを低コストで上回る。
- TransXNet-B は ImageNet-1K で top-1 84.6% を達成、8.3G FLOPs、48.0M パラメータで強力な精度-コストのバランスを提供し、同等クラスのバックボーンを上回る。
- ImageNet-1K-V2 では TransXNet バリアントがより良い一般化と転移性を示し、tiny/small/base 構成で顕著な利得。
- COCO オブジェクト検出と Mask R-CNN 分割では、TransXNet バックボーンが同程度の計算で同業他社を上回り、特に中〜大きな物体でグローバル-ローカルのダイナミクスの利点を示す。
- ADE20K セマンティック分割では TransXNet-T/S/B がそれぞれ mIoU 45.5%/48.5%/49.9% を達成し、ベースラインと比較して競争力のあるまたは低い FLOPs。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。