[論文レビュー] ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding
ULIP-2 は、BLIP-2 を用いてレンダリングされた 2D ビューから言語を生成することで 3D マルチモーダル事前学習の言語監視を自動化し、ヒトの 3D アノテーションなしで強力なゼロショットおよび標準の 3D 分類を実現し、大規模な三方言語データ(トライモーダル・トリップレッツ)を公開します。
Recent advancements in multimodal pre-training have shown promising efficacy in 3D representation learning by aligning multimodal features across 3D shapes, their 2D counterparts, and language descriptions. However, the methods used by existing frameworks to curate such multimodal data, in particular language descriptions for 3D shapes, are not scalable, and the collected language descriptions are not diverse. To address this, we introduce ULIP-2, a simple yet effective tri-modal pre-training framework that leverages large multimodal models to automatically generate holistic language descriptions for 3D shapes. It only needs 3D data as input, eliminating the need for any manual 3D annotations, and is therefore scalable to large datasets. ULIP-2 is also equipped with scaled-up backbones for better multimodal representation learning. We conduct experiments on two large-scale 3D datasets, Objaverse and ShapeNet, and augment them with tri-modal datasets of 3D point clouds, images, and language for training ULIP-2. Experiments show that ULIP-2 demonstrates substantial benefits in three downstream tasks: zero-shot 3D classification, standard 3D classification with fine-tuning, and 3D captioning (3D-to-language generation). It achieves a new SOTA of 50.6% (top-1) on Objaverse-LVIS and 84.7% (top-1) on ModelNet40 in zero-shot classification. In the ScanObjectNN benchmark for standard fine-tuning, ULIP-2 reaches an overall accuracy of 91.5% with a compact model of only 1.4 million parameters. ULIP-2 sheds light on a new paradigm for scalable multimodal 3D representation learning without human annotations and shows significant improvements over existing baselines. The code and datasets are released at https://github.com/salesforce/ULIP.
研究の動機と目的
- マルチモーダル3D学習における言語監視のスケーラビリティのボトルネックを解消する。
- 手動アノテーションなしで3Dオブジェクトから包括的な言語記述を生成する完全自動のパイプラインを提案する。
- 3D点群、レンダリング画像、言語記述を事前に整列された固定の視覚-言語空間に整合させる。
- 公開されたトライモーダル・トリップレットを用いてObjaverseとShapeNetでスケーラビリティと有効性を示す。
提案手法
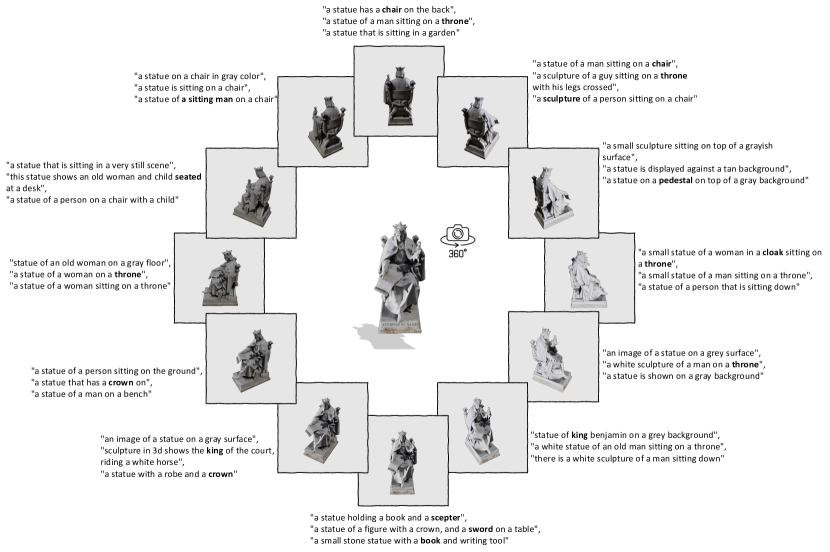
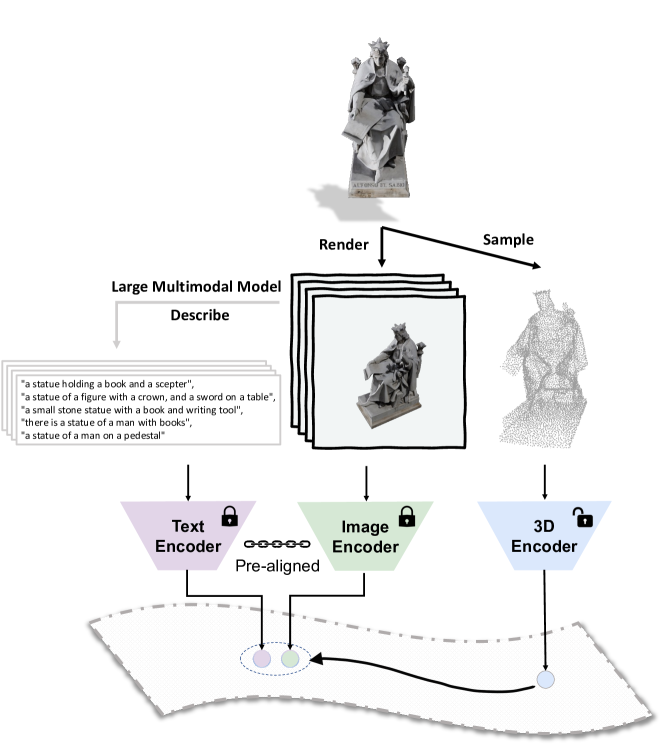
- 各3Dオブジェクトから固定セットの包括的な2Dビューをレンダリングして画像データを提供する。
- 各レンダリング画像に対してBLIP-2を用いて記述的な文を生成し、上位k文を言語モダリティとして集約する。
- 3Dモダリティ入力として3D点群を抽出し、事前整列済みの画像/テキスト特徴と整合させるよう3Dエンコーダを学習する。
- SLIPの画像/テキストエンコーダを固定して共通の視覚-言語特徴空間を提供する。
- L_P2I と L_P2T の2つの対比損失で学習し、それぞれ3Dと画像特徴、3Dとテキスト特徴の整合を促進する。
実験結果
リサーチクエスチョン
- RQ1大規模マルチモーダルモデルから自動生成されたスケーラブルな言語記述は、3Dマルチモーダル事前学習に十分な監督を提供し得るのか?
- RQ2言語の豊かさ(包括的な視点記述)がゼロショットおよび標準分類タスクにおける3D表現品質に与える影響は何か?
- RQ3ULIP-2 は人間の3Dアノテーションなしで、大規模3Dデータセットや異なるバックボーンでどのように性能を発揮するのか?
- RQ4既存の3Dデータから派生した三方データセットを公開することの利点と制約は何か?
主な発見
- ULIP-2 は ModelNet40 で 74.0% の top-1 ゼロショット精度を達成(人間による 3D アノテーションなし)。
- ScanObjectNN では ULIP-2 がわずか 1.4M パラメータで全体精度 91.5% を達成。
- ULIP-2 はバックボーンとデータセットを問わず ULIP よりも上回り、包括的視点の言語記述の利点を示している。
- ShapeNet と Objaverse のために、ULIP-2 は大規模な tri-modal triplets(Objaverse/ShapeNet Triplets)を公開できるようにする。
- ゼロショットおよび標準の3D分類の利得は、バックボーンの選択(Point-BERT、PointNeXt)およびビュー/キャプションの数に対して頑健である。
- BLIP-2 の使用は BLIP より強力な結果をもたらし、より有能な大規模マルチモーダルモデルの選択を裏付けている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。