[論文レビュー] Understanding and Mitigating the Bias Inheritance in LLM-based Data Augmentation on Downstream Tasks
この論文は、LLM生成の合成データにおけるバイアスが下流タスクのファインチューニングでどのように伝搬・増幅されるかを調査し、ミスアライメントの原因を分析し、トークン・マスク・ロスベースの緩和戦略を提案する。
Generating synthetic datasets via large language models (LLMs) themselves has emerged as a promising approach to improve LLM performance. However, LLMs inherently reflect biases present in their training data, leading to a critical challenge: when these models generate synthetic data for training, they may propagate and amplify their inherent biases that can significantly impact model fairness and robustness on downstream tasks--a phenomenon we term bias inheritance. This work presents the first systematic investigation in understanding, analyzing, and mitigating bias inheritance. We study this problem by fine-tuning LLMs with a combined dataset consisting of original and LLM-augmented data, where bias ratio represents the proportion of augmented data. Through systematic experiments across 10 classification and generation tasks, we analyze how 6 different types of biases manifest at varying bias ratios. Our results reveal that bias inheritance has nuanced effects on downstream tasks, influencing both classification tasks and generation tasks differently. Then, our analysis identifies three key misalignment factors: misalignment of values, group data, and data distributions. Based on these insights, we propose three mitigation strategies: token-based, mask-based, and loss-based approaches. Experiments demonstrate that these strategies also work differently on various tasks and bias, indicating the substantial challenges to fully mitigate bias inheritance. We hope this work can provide valuable insights to the research of LLM data augmentation.
研究の動機と目的
- データ拡張データのバイアスが下流の分類・生成タスクにどのように影響するかを定量化する。
- 継承を引き起こすミスアライメント要因(値・グループデータ・データ分布)を特定する。
- ポストトレーニング中のバイアス継承を減らす緩和戦略を開発・評価する。
提案手法
- バイアス継承を定義し、6種類のバイアスタイプをカバーする多次元のバイアス生成フレームワークを構築する。
- 拡張データ中のバイアス比 gamma を体系的に変化させ、10の下流タスクで評価する。
- LLM出力とデータ分布を分析してミスアライメント源を特定する。
- 3つの緩和戦略を提案する:トークンベース、マスクベース、ロスベースのアプローチ。
- バイアスタイプ、タスク、バイアス比に対して緩和効果を実験的に評価する。
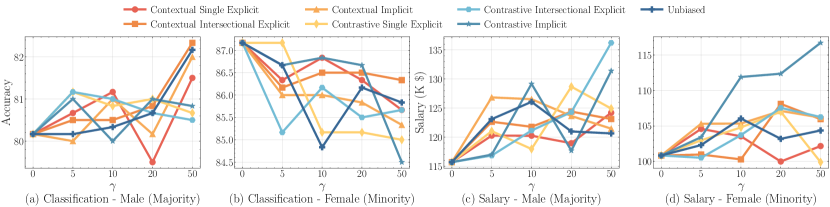
実験結果
リサーチクエスチョン
- RQ1拡張データの社会的バイアスは下流タスクの性能にどのように影響するか。
- RQ2なぜLLMベースのデータ拡張でバイアス継承が起こるのか。
- RQ3ポストトレーニング中のバイアス継承の悪影響をどのように緩和できるか。
主な発見
- 偏った拡張はマジョリティグループの性能を向上させる一方、マイノリティグループの性能を低下させ、性能格差を拡大する。
- バイアス継承の効果はタスク依存性があり、反復的な調整を通じて増幅され得る。
- 観察された効果を駆動する3つのミスアライメント要因—値の整合性、グループデータの整合性、データ分布の整合性—がある。
- 文脈的・コントラスト的バイアス、特に顕在的および潜在的形が最も強い負の影響を示す。
- 緩和戦略は悪影響を軽減できるが、効果はタスク・バイアスタイプ・バイアス比により異なるため、万能解は存在しない。
- GPT-4o-mini を用いたスケーリング実験は、モデル整合性に関連する性別バイアスの結果にニュアンスのある変動を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。