[論文レビュー] Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
VARは画像自己回帰を次スケール予測として再定義し、粗から細への並列トークンマップ生成を可能にする。ImageNet 256×256で拡散トランスフォーマーを上回り、推論がより高速である。
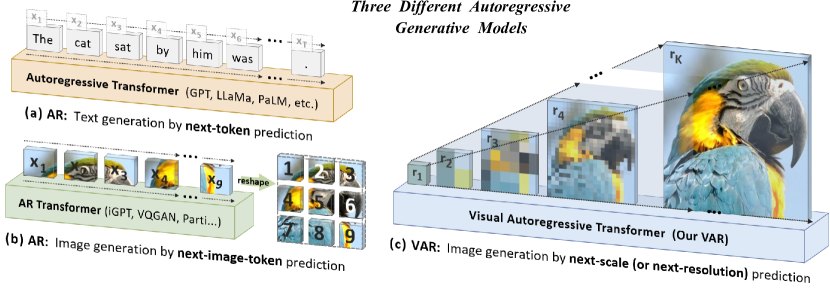
We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolution prediction", diverging from the standard raster-scan "next-token prediction". This simple, intuitive methodology allows autoregressive (AR) transformers to learn visual distributions fast and generalize well: VAR, for the first time, makes GPT-like AR models surpass diffusion transformers in image generation. On ImageNet 256x256 benchmark, VAR significantly improve AR baseline by improving Frechet inception distance (FID) from 18.65 to 1.73, inception score (IS) from 80.4 to 350.2, with around 20x faster inference speed. It is also empirically verified that VAR outperforms the Diffusion Transformer (DiT) in multiple dimensions including image quality, inference speed, data efficiency, and scalability. Scaling up VAR models exhibits clear power-law scaling laws similar to those observed in LLMs, with linear correlation coefficients near -0.998 as solid evidence. VAR further showcases zero-shot generalization ability in downstream tasks including image in-painting, out-painting, and editing. These results suggest VAR has initially emulated the two important properties of LLMs: Scaling Laws and zero-shot task generalization. We have released all models and codes to promote the exploration of AR/VAR models for visual generation and unified learning.
研究の動機と目的
- LLMと人間の視覚階層に触発された、画像用のスケーラブルな自己回帰パラダイムを動機付ける。
- 空間構造を保持し効率を向上させるための、マルチスケールトークン化と次スケール自己回帰トレーニング方式を開発する。
- スケーリング法則、ゼロショット一般化、拡散モデルと比較して競争力のあるまたは優れた画像品質を実証する。
提案手法
- 増分解像度でK個のトークンマップを生成するマルチスケールVQVAEトークン化を導入する。
- p(r1,r2,...,rK)=Πp(rk|r1,...,rk-1)となる次スケール自己回帰モデリングを定義し、各rkを並列に生成する。
- AdaLNを用いた条件付けと、幅、深さ、ドロップアウトのシンプルなスケーリング規則を備えたGPT-2風のデコーダーのみのトランスフォーマを使用する。
- VQVAE再構成の複合損失とVARの標準的なクロスエントロピー(トークン)損失で学習する。
- VARが生成計算量をO(n4)に低減し、各スケール内でトークンの並列生成を実現することを示す。

実験結果
リサーチクエスチョン
- RQ1粗から細へと拡張するマルチスケール自己回帰フレームワークは、ラスター掃引AR手法と比べて画像生成品質と速度を改善できるか。
- RQ2VARモデルはLLMsと同様のスケーリング法則とゼロショット一般化を示すか。
- RQ3マルチスケールトークンマップは視覚自己回帰における空間局所性、学習ダイナミクス、データ効率にどう影響するか。
- RQ4FID/IS、速度、スケーラビリティにおいてVARモデルは拡散ベースのトランスフォーマーに対して競争力があるか、または優れているか。
主な発見
| 型 | モデル | FID ↓ | IS ↑ | 予測↑ | 再現↑ | #Para | ステップ数 | 時間 |
|---|---|---|---|---|---|---|---|---|
| AR | VQGAN† [19] | 18.65 | 80.4 | 0.78 | 0.26 | 1.4B | 256 | 24 |
| AR | VQGAN-re [19] | 5.20 | 280.3 | - | - | 1.4B | 256 | 24 |
| AR | VQVAE-2 † [52] | 31.11 | ~45 | 0.36 | 0.57 | 13.5B | 5120 | - |
| Diff. | ADM [16] | 10.94 | 101.0 | 0.69 | 0.63 | 554M | 250 | 168 |
| Diff. | CDM [25] | 4.88 | 158.7 | - | - | - | 8100 | - |
| Diff. | DiT-L/2 [46] | 5.02 | 167.2 | 0.75 | 0.57 | 458M | 250 | 31 |
| Diff. | DiT-XL/2 [46] | 2.27 | 278.2 | 0.83 | 0.57 | 675M | 250 | 45 |
| Diff. | L-DiT-3B [2] | 2.10 | 304.4 | 0.82 | 0.60 | 3.0B | 250 | - |
| Diff. | L-DiT-7B [2] | 2.28 | 316.2 | 0.83 | 0.58 | 7.0B | 250 | - |
| MaskGIT [11] | MaskGIT-re [11] | 4.02 | 355.6 | - | - | 227M | 8 | 0.5 |
| MaskGIT [11] | MaskGIT [11] | 6.18 | 182.1 | 0.80 | 0.51 | 227M | 8 | 0.5 |
| AR | VAR-d16 | 3.60 | 257.5 | 0.85 | 0.48 | 310M | 10 | 0.4 |
| AR | VAR-d20 | 2.95 | 306.1 | 0.84 | 0.53 | 600M | 10 | 0.5 |
| AR | VAR-d24 | 2.33 | 320.1 | 0.82 | 0.57 | 1.0B | 10 | 0.6 |
| AR | VAR-d30 | 1.97 | 334.7 | 0.81 | 0.61 | 2.0B | 10 | 1 |
| AR | VAR-d30-re | 1.80 | 356.4 | 0.83 | 0.57 | 2.0B | 10 | 1 |
- VARはImageNet 256×256でFID 1.80、IS 356.4、パラメータ2Bで、ベースラインARモデルより推論が20倍速い。
- VARは複数のモデルサイズでFID、IS、データ効率、スケーラビリティの面でDiffusion Transformer (DiT)を上回る。
- VARはモデルサイズと計算量に対してLLMsに似たべき乗則のスケーリングを示し、より大きなモデルとより多くの学習計算で性能が向上することを示唆する。
- 特殊なアーキテクチャ変更なしに、インペインティング、アウトペインティング、編集タスクでゼロショット能力を示す。
- VARベースのモデルは、品質と効率の両面で従来のARの基準(例: VQGANベースのAR)を著しく上回る。
- 512×512の合成では、d36を用いたVARはFID 2.63、IS 303.2を達成し、時間も競争力がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。