[論文レビュー] VLM See, Robot Do: Human Demo Video to Robot Action Plan via Vision Language Model
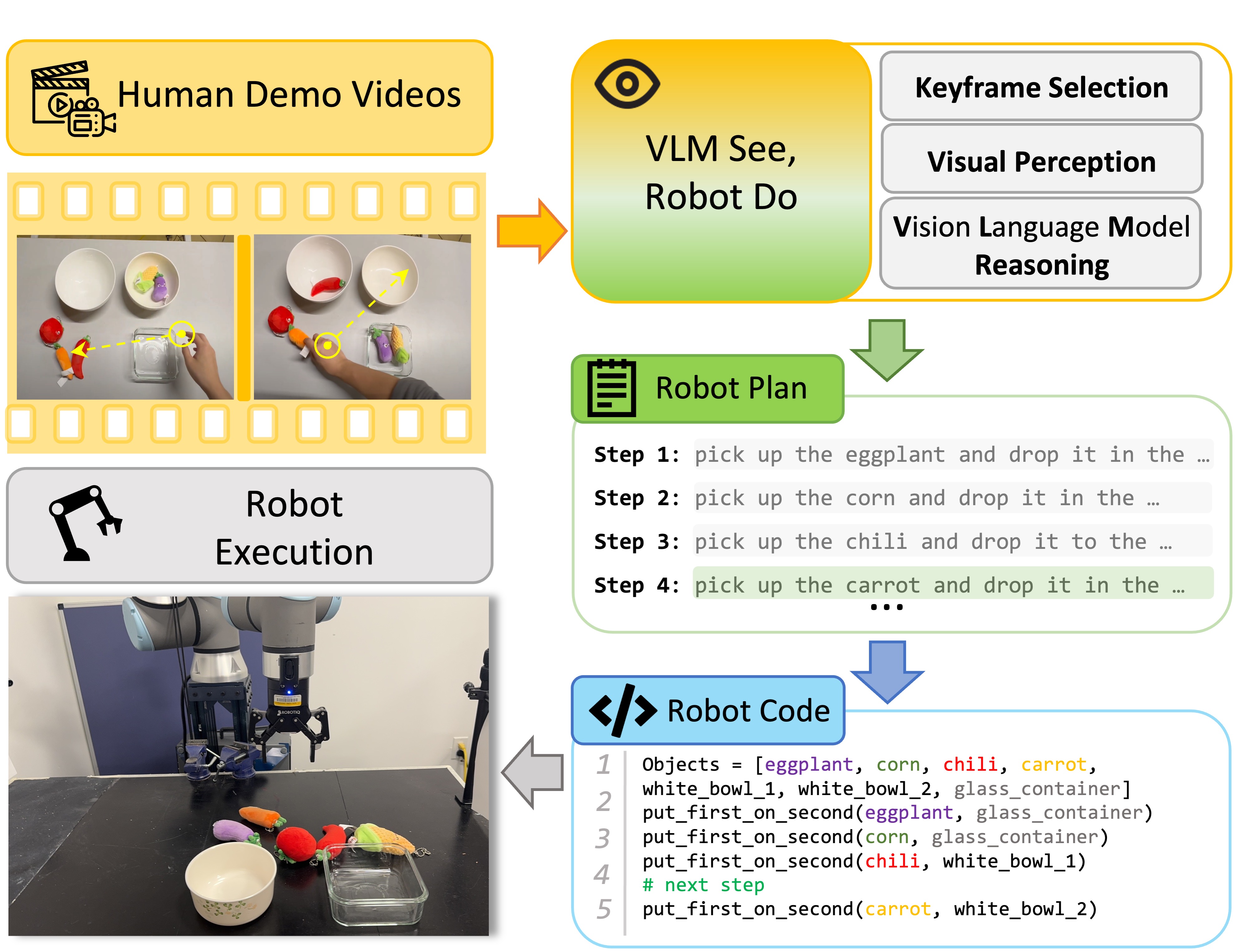
SeeDoは、キーフレーム選択と視覚認識プロンプトを組み込んだ vision-language model パイプラインを用いて、人間のデモンストレーション動画をロボットのタスク計画へ変換し、シミュレーションと実機ロボット上で、言語モデルのプログラムを通じて実行される。
Vision Language Models (VLMs) have recently been adopted in robotics for their capability in common sense reasoning and generalizability. Existing work has applied VLMs to generate task and motion planning from natural language instructions and simulate training data for robot learning. In this work, we explore using VLM to interpret human demonstration videos and generate robot task planning. Our method integrates keyframe selection, visual perception, and VLM reasoning into a pipeline. We named it SeeDo because it enables the VLM to ''see'' human demonstrations and explain the corresponding plans to the robot for it to ''do''. To validate our approach, we collected a set of long-horizon human videos demonstrating pick-and-place tasks in three diverse categories and designed a set of metrics to comprehensively benchmark SeeDo against several baselines, including state-of-the-art video-input VLMs. The experiments demonstrate SeeDo's superior performance. We further deployed the generated task plans in both a simulation environment and on a real robot arm.
研究の動機と目的
- 長期的な人間デモンストレーション動画から視覚と言語のモデルを用いたロボット学習を動機付ける。
- 動画をサブタスク分解を通じてロボットのタスク計画に解釈するパイプラインを開発する。
- VLMの知覚強化推論を通じて、動画処理と空間関係の課題を緩和する。
- SeeDoを、長期的タスクに関する多様なシナリオで最先端の動画VLMとベンチマークする。
提案手法
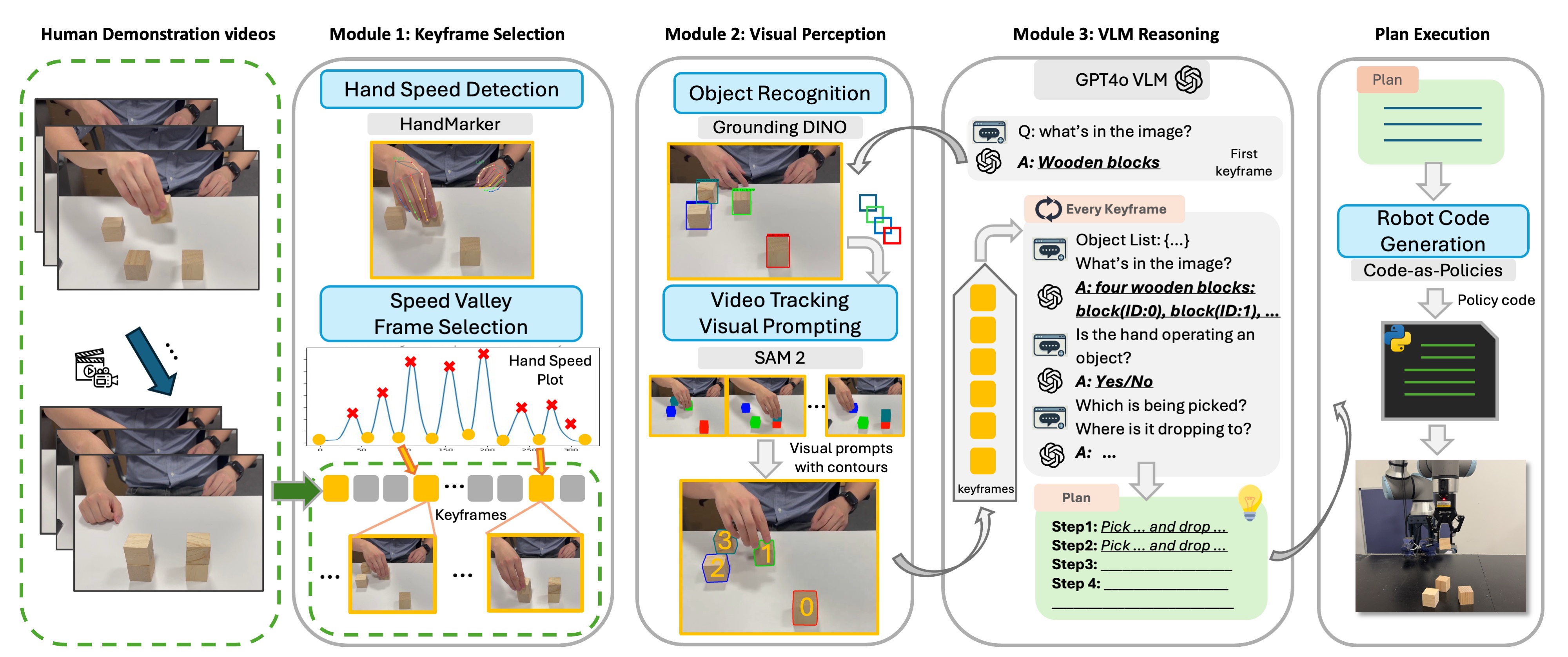
- 三部構成のSeeDoパイプライン:Keyframe Selection、Visual Perception、VLM Reasoningを導入する。
- 手の動き速度に基づくキーフレーム抽出を用いて重要なアクションフレームを捉える。
- 物体追跡と視覚プロンプト(輪郭、ID、中心点)を適用してVLMの認識を強化する。
- GPT-4oをチェーン・オブ・ソート推論で用いてタスク計画を生成する。
- 生成された計画を Language Model Programs (LMPs) に変換し、ロボティクスAPIを介して実行する。
- シミュレーション(Pybullet)とUR10e実機で三つのタスクを評価する。
実験結果
リサーチクエスチョン
- RQ1視覚-言語モデルは、人間デモンストレーション動画を解釈して実行可能なロボット計画を生成できるか?
- RQ2キーフレーム選択と視覚認識モジュールを追加することで、VLMベースの計画における時間的・空間的推論は改善されるか?
- RQ3SeeDoは長期的タスクにおいて、最先端の動画VLMと比較してどうであるか?
- RQ4生成されたタスク計画は、シミュレーションと実機の両方へ転用可能か?
主な発見
- SeeDoは、 TSR、FSR、SSR のすべてのタスクで、ベースライン(クローズドソースおよびオープンソースの動画VLM)を上回る。
- SSRsは木製ブロックで52.48%以上を超え、衣類整理で66.50%を超えるSeeDo構成を達成。
- SeeDoは野菜整理で60.53% TSRとFSR、80.40% SSRを達成し、他モデルを上回る。
- 視覚プロンプトは空間推論を著しく改善し、プロンプトなしのSeeDoと比較して空間誤差率を低減。
- アブレーションにより、キーフレームサンプリングと手検出ベースのキーフレームが文脈と性能の維持に重要であることが示された。
- 生成されたタスク計画は、シミュレーションと実機のUR10eの両方でLMPを用いて実行可能である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。