[論文レビュー] VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
本論文は VoiceFilter を紹介する。ターゲット話者埋め込みを用いた話者条件付きスペクトログラムマスキングを行う二ネットワークシステムで、多話者混合からターゲット音声を効果的に抽出し、クリーン音声への影響を最小限に抑えつつ ASR の WER を改善する。
In this paper, we present a novel system that separates the voice of a target speaker from multi-speaker signals, by making use of a reference signal from the target speaker. We achieve this by training two separate neural networks: (1) A speaker recognition network that produces speaker-discriminative embeddings; (2) A spectrogram masking network that takes both noisy spectrogram and speaker embedding as input, and produces a mask. Our system significantly reduces the speech recognition WER on multi-speaker signals, with minimal WER degradation on single-speaker signals.
研究の動機と目的
- 事前に話者の数を知らずに、ターゲット音声分離を動機づける。
- ターゲット話者の頑健な埋め込みを生成する話者エンコーダを開発する。
- ターゲット話者の埋め込みを用いて干渉を抑制するスペクトログラムマスキングネットワークを設計する。
- 単一話者の性能を維持しつつ、多話者データでWER改善を実証する。
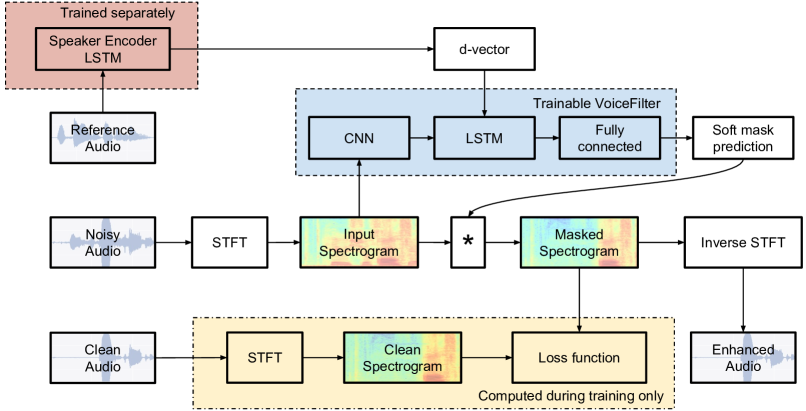
提案手法
- log-mel特徴量から256次元d-vectorを生成する3層LSTM話者エンコーダを訓練する。
- ターゲット話者d-vectorとノイズの大きさスペクトログラムを条件に、ソフトマスクを予測するスペクトログラムマスキングネットワークを訓練する。
- 畳み込み層とLSTM層の間にd-vectorを挿入して、時刻-周波数処理を保持する。
- 強化されたスペクトログラムとターゲットクリーンの大きさスペクトログラム間の再構成損失でマスクを最適化し、元の位相を用いて波形を再構成する。
- 訓練時には音声を16 kHzで3秒セグメントで処理する。
- 評価はWord Error Rate (WER)とSource to Distortion Ratio (SDR)で行う。
実験結果
リサーチクエスチョン
- RQ1ターゲット話者埋め込みは、妨害話者の数を知らなくてもエンドツーエンド分離を可能にするか?
- RQ2話者条件付けは、伝統的な分離手法と比べてWERとSDRにどのように影響するか?
- RQ3さまざまな時系列モデル(LSTMなし、単方向LSTM、双方向LSTM)による性能への影響は?
- RQ4より大きく多様なデータセットでの訓練は、ドメイン間で一般化するか(LibriSpeech から VCTK など)?
主な発見
| Model | Dataset | Clean WER (%) | Noisy WER (%) |
|---|---|---|---|
| No VoiceFilter | LibriSpeech | 10.9 | 55.9 |
| VoiceFilter: no LSTM | LibriSpeech | 12.2 | 35.3 |
| VoiceFilter: LSTM | LibriSpeech | 12.2 | 28.2 |
| VoiceFilter: bi-LSTM | LibriSpeech | 11.1 | 23.4 |
| No VoiceFilter | VCTK | 6.1 | 60.6 |
| Trained on VCTK | VCTK | 21.1 | 37.0 |
| Trained on LibriSpeech | VCTK | 5.9 | 34.3 |
- 双方向LSTM VoiceFilterがノイズ付きLibriSpeechデータで最良のWERを達成(23.4% vs uni-LSTMの28.2%、no LSTMの35.3%)
- VoiceFilterはLibriSpeech二話者混合でノイズありWERを55.9%から23.4%に低下させる(LibriSpeech訓練)
- LibriSpeechでは、ノイズありWERの改善が最良モデルで相対的に58.1%の削減をもたらし、クリーンWERはクリーンベースラインに近いまま(11.1% vs 10.9%)
- VCTKでは、LibriSpeechで訓練するとNoisy WERが60.6%から34.3%へ改善し、クリーンWERはわずかに悪化(5.9% vs 6.1%);VCTKで訓練するとクリーンWERが高くなる(21.1%)
- SDRの結果はWER傾向と一致し、bi-LSTMがLibriSpeechで最も高い平均/中央値SDR(17.9 dB / 12.6 dB)を達成。
- VoiceFilterはspeaker embeddingsを用いることでPermutation-invariant lossベースラインを上回り、ターゲット話者条件付けの利点を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。