[論文レビュー] VRSBench: A Versatile Vision-Language Benchmark Dataset for Remote Sensing Image Understanding
VRSBenchはリモートセンシング向けの大規模で人間検証済みのビジョン-ランゲージベンチマークを提供します。画像29,614件、キャプション、オブジェクト参照、そして123,221件のVQAペアを含み、キャプション作成、グラウンディング、VQAの評価が行われます。
We introduce a new benchmark designed to advance the development of general-purpose, large-scale vision-language models for remote sensing images. Although several vision-language datasets in remote sensing have been proposed to pursue this goal, existing datasets are typically tailored to single tasks, lack detailed object information, or suffer from inadequate quality control. Exploring these improvement opportunities, we present a Versatile vision-language Benchmark for Remote Sensing image understanding, termed VRSBench. This benchmark comprises 29,614 images, with 29,614 human-verified detailed captions, 52,472 object references, and 123,221 question-answer pairs. It facilitates the training and evaluation of vision-language models across a broad spectrum of remote sensing image understanding tasks. We further evaluated state-of-the-art models on this benchmark for three vision-language tasks: image captioning, visual grounding, and visual question answering. Our work aims to significantly contribute to the development of advanced vision-language models in the field of remote sensing. The data and code can be accessed at https://github.com/lx709/VRSBench.
研究の動機と目的
- 既存のリモートセンシング視覚-言語データセットの制約を解決する(単一タスクへの焦点、オブジェクト詳細の低さ、品質管理の課題)
- 詳細なキャプション、オブジェクト参照、およびオープンエンドVQAを備えた大規模で統一されたデータセットを提供する
- リモートセンシングでのキャプション作成、グラウンディング、VQAにわたる視覚-言語モデルの訓練と評価を可能にする
- 注釈品質を保証するための人間検証を伴う半自動データ収集パイプラインを提案する
- 3つのベンチマーク(キャプション作成、グラウンディング、VQA)と最先端モデルのベースライン評価を提供する
提案手法
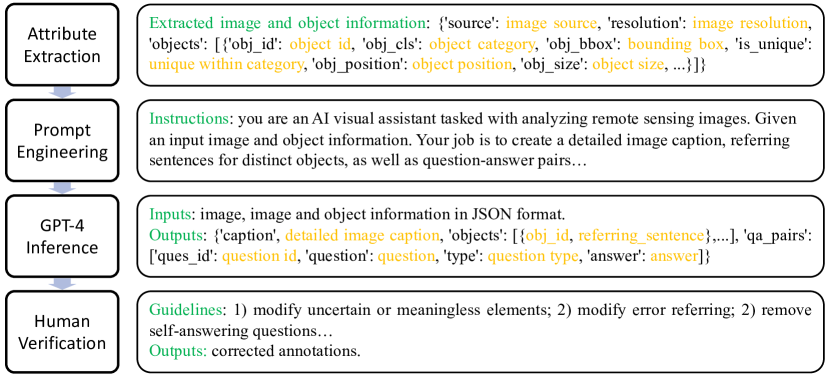
- 属性抽出、プロンプトエンジニアリング、GPT-4推論、そして人間検証の4段階からなる半自動データ収集パイプラインを導入する
- DOTA-v2およびDIORをオブジェクト属性とバウンディングボックスのソースとして使用し、指向性境界ボックス(OBB)によるグラウンディングを可能にする
- キャプション、オブジェクト参照文、QAペアを生成するためのGPT-4V用の慎重なプロンプトを設計し、以降人間による検証を行う
- 詳細なキャプション、1–5件の画像あたりのオブジェクト参照文、および3–10件のVQAペアを含む注釈を提供する
- 3つのベンチマーク(VRSBench-Cap、VRSBench-Ref、VRSBench-VQA)を構築し、VRSBenchでのファインチューニングを含むベースラインモデルを評価する
- 標準指標を用いて評価(キャプション作成:BLEU、ROUGE_L、METEOR、CIDEr;グラウンディング:Acc@IoU;VQA:質問タイプごとの正解率)

実験結果
リサーチクエスチョン
- RQ1現在のビジョン-ラングエージモデルは、VRSBenchで評価したとき、リモートセンシングの詳細なキャプション、グラウンディング、VQAタスクでどのように性能を示すか?
- RQ2VRSBenchでファインチューニングした一般目的のビジョン-言語モデルは、キャプション作成、グラウンディング、VQAのすべてで性能を大幅に向上させるか?
- RQ3グロウンディングとVQAタスク中に、明示的なオブジェクト情報(属性、境界ボックス)を含めることの相対的な影響はどれくらいか?
- RQ4Explicit object情報なしのプロンプトを与えた場合、GPT-4VはこれらのタスクでVRSBenchで訓練されたモデルと比較してどの程度性能を発揮するか?
主な発見
- VRSBenchはリモートセンシング画像に対して、キャプション作成、グラウンディング、VQAの3つのタスクで大規模な評価を可能にする。
- ファインチューニングされたLVM(例:LLaVA-1.5)は、キャプション作成指標で最も高い値を達成(BLEU-1 48.1、CIDEr 33.9)、キャプションは平均52語。
- GPT-4Vは強力なキャプション作成とVQAの結果を示す(キャプション:BLEU-1 37.2、CIDEr 19.1、VQA平均65.6)一方、オブジェクト属性が提供されていない場合はグラウンディングが劣る。
- グラウンディングの結果は、ファインチューニング済みモデルがベースラインを上回り、唯一のオブジェクト参照が非ユニークよりも容易である傾向がある(例:GeoChatは一部設定で全体のAcc@0.5が39.6%)。
- VQAの結果は、VRSBenchでのファインチューニングによる大幅な利得を示す(GeoChat w ftの平均正答率60.6%、GPT-4Vは平均で65.6%)。
- データセットは29,614画像、29,614キャプション、52,472参照文、123,221のVQAペアを含み、512×512 RGB画像を使用。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。