[論文レビュー] We're Different, We're the Same: Creative Homogeneity Across LLMs
本研究は、標準化された創造性テストを用いて広範なLLMと人間の創造的アウトプットを比較し、LLMの応答はモデル間で人間間より著しく均質であることを示している。
Numerous powerful large language models (LLMs) are now available for use as writing support tools, idea generators, and beyond. Although these LLMs are marketed as helpful creative assistants, several works have shown that using an LLM as a creative partner results in a narrower set of creative outputs. However, these studies only consider the effects of interacting with a single LLM, begging the question of whether such narrowed creativity stems from using a particular LLM -- which arguably has a limited range of outputs -- or from using LLMs in general as creative assistants. To study this question, we elicit creative responses from humans and a broad set of LLMs using standardized creativity tests and compare the population-level diversity of responses. We find that LLM responses are much more similar to other LLM responses than human responses are to each other, even after controlling for response structure and other key variables. This finding of significant homogeneity in creative outputs across the LLMs we evaluate adds a new dimension to the ongoing conversation about creativity and LLMs. If today's LLMs behave similarly, using them as a creative partners -- regardless of the model used -- may drive all users towards a limited set of "creative" outputs.
研究の動機と目的
- LLMsを1つのグループとして見た場合、人間と比較して創造的アウトプットの変動性が多い・少ない・同程度かを評価する。
- 複数のモデルファミリーとプロンプトに跨って、cross-LLMの均質性が持続するかを評価する。
- LLMと人間の創造的アウトプットにおける内容の類似性と構造的類似性を分離する。
提案手法
- 標準化された創造性テスト(AUT、Forward Flow、DAT)を用いて、人間と7つ以上の多様なLLMから創造的な回答を誘発する。
- 自動埋め込み(GloVe)とコサイン距離を用いて個々の独創性を計算し、新規性を定量化する。
- 埋め込まれた回答の意味的類似性を全対のコサイン距離を用いて測定し、母集団レベルの変動性を評価する。
- 独創性と変動性の差に対してp < 0.01でWelch’s t-testを用いてLLMsと人間を比較する。
- 複数のAUTプロンプト版本をテストし、語長/分布でフィルタリングして応答構造を制御する。
- TSNEとクラスタリングを用いて応答空間を可視化し、変動性の所見を裏付ける。
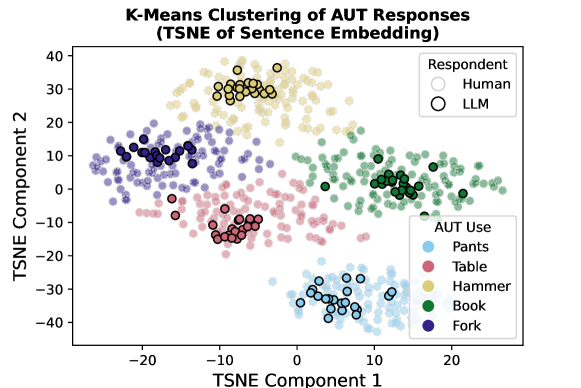
実験結果
リサーチクエスチョン
- RQ1AUT、Forward Flow、DATにおける創造的アウトプットの平均独創性で、LLMsと人間は異なるか。
- RQ2同じプロンプトに応答した場合、LLMの出力はモデル間で人間の出力より均質か。
- RQ3異なるモデルファミリーに制限した場合、またはプロンプト構造を調整した場合に、cross-LLMの均質性は持続するか。
- RQ4プロンプト設計はLLMs間の創造性の均質化を緩和または逆転させることができるか。
主な発見
- LLMsはAUTとDATの独創性で人工よりわずかに優れる一方、Forward Flowでは人間がLLMsよりわずかに優れる。
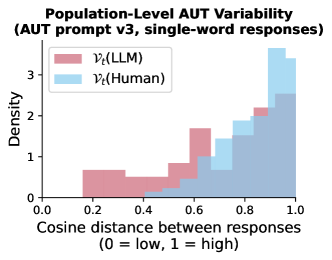
- テスト全体で、LLMsは人間より応答の母集団レベルの変動性が著しく低く、より均質なアウトプットを示す。
- プロンプト設計はLLMの創造性と変動性を変えることができるが、全体として人間は依然としてより変動的である。たとえ1語のAUT応答でさえLLMの変動性が低減する。
- 語彙の重複分析はLLMsが応答間でより多くの語彙内容を共有することを示し、意味的類似性の向上に寄与する。
- 制御分析は、AUT応答構造を考慮し、モデルファミリー間を比較しても均質性が持続することを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。