[論文レビュー] What do you learn from context? Probing for sentence structure in contextualized word representations
本論文はエッジプロービングを導入し、CoVe、ELMo、GPT、BERTなどの文脈化語彙表現に含まれる合成情報を固定的な文脈埋め込みから言語的エッジを予測することで分析し、統語情報が意味情報より強い信号を示すことと、ELMoやBERTのような深層モデルにおける非局所情報の証拠を明らかにする。
Contextualized representation models such as ELMo (Peters et al., 2018a) and BERT (Devlin et al., 2018) have recently achieved state-of-the-art results on a diverse array of downstream NLP tasks. Building on recent token-level probing work, we introduce a novel edge probing task design and construct a broad suite of sub-sentence tasks derived from the traditional structured NLP pipeline. We probe word-level contextual representations from four recent models and investigate how they encode sentence structure across a range of syntactic, semantic, local, and long-range phenomena. We find that existing models trained on language modeling and translation produce strong representations for syntactic phenomena, but only offer comparably small improvements on semantic tasks over a non-contextual baseline.
研究の動機と目的
- 語彙的事前情報を超えて、各トークン位置で文脈化語彙表現がどんな情報を符号化しているかを調査する。
- 4つのモデル(CoVe、ELMo、GPT、BERT)における構文的・意味的・局所的・長距離的現象の符号化を評価する。
- 文脈化表現を語彙ベースラインと比較して、文脈による利得を分離する。
提案手法
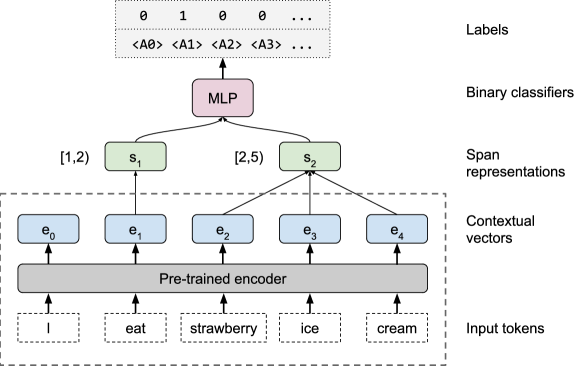
- エッジプロービングフレームワークを提案し、固定的な文脈埋め込みを用いてトークン spans の間のラベル付きエッジを予測する。
- スパンベースのプーリング機構と2層のMLP分類器を開発し、スパン表現からエッジラベルを予測する。
- 構文/意味パイプラインから派生した8つのラベリングタスク(POS、 constituents、 dependencies、 NER、 SRL、 coreference、 SPR、 relation classification)を横断して評価する。
- 複数のデータセット(OntoNotes、UD、SPR1/SPR2、SemEval 2010)を使用し、語彙ベースラインおよびCNN/直交化/ランダム化バリアントと比較して、アーキテクチャと事前学習の効果を分離する。
- エンコーダをファインチューニングせず、結合表現(cat)または混合表現(mix)を用いて、CoVe、ELMo、GPT、BERT の4モデルをプローブする。
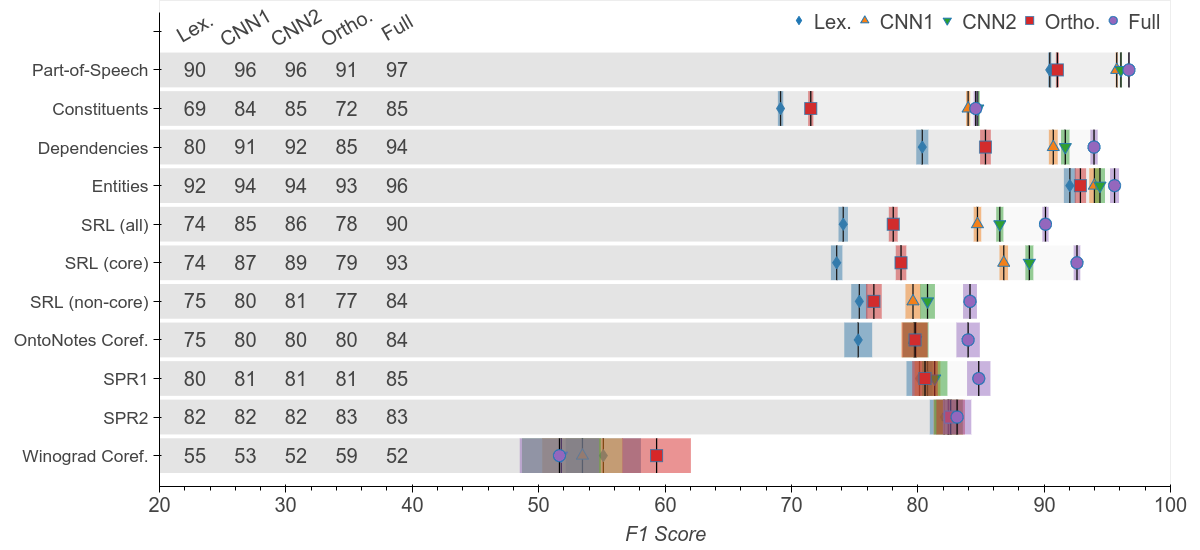
実験結果
リサーチクエスチョン
- RQ1文脈化埋め込みは、文中の各位置でどんな言語情報を符号化しているのか?
- RQ2文脈表現は主に構文的か意味的か、局所的か長距離か?
- RQ3異なる事前学習目的とアーキテクチャ(CoVe、ELMo、GPT、BERT)が、タスク全体でのエッジ予測性能にどのように影響するか?
- RQ4観測された利得を、語彙ベースラインや単純なアーキテクチャ制御(CNN、ランダム化)でどの程度説明できるか?
- RQ5より深いモデル(例:BERT-large)は、語義タスク(コアリファレンスや SPR など)で意味的タスクに対して構文タスクより著しい改善をもたらすか?
主な発見
- 文脈化埋め込みは一般に語彙ベースラインを上回り、最大の利得は依存関係や成分ラベリングといった構文タスクで見られる。
- ELMo と GPT は CoVe より高い性能を達成し、ELMo が多くのタスクで通常優位に立ち、GPT が混合特徴を用いると関係分類とコアリファレンスで優れた成果を示す。
- 層表現のスカラー混合(mix)は、単純な結合(cat)に比べて、BERT や GPT のような深いトランスフォーマーで性能を向上させ、BERT-large は多くのタスクでELMoを顕著に上回ることが多い(例:OntoNotes コアリファレンス)。
- BERT-large は OntoNotes コアリファレンスで特に大きな利得を示し、他のタスクでも合理的な改善を示唆するなど、より深い無監視モデルが意味理解をある程度支援することを示唆している。
- 非局所的な文脈は実質的に寄与する:小さな畳み込みビューを語彙ベースラインに追加することで、多くの構文タスクで完全モデルの利得の大部分を回収する一方、意味的タスクは長距離情報への依存がより大きい。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。