[論文レビュー] What's in a Name? Auditing Large Language Models for Race and Gender Bias
この論文は最先端のLLMs(GPT-4を含む)を14分野にわたる42のプロンプトを用いて評価し、アドバイス生成における名前ベースの人種および性別バイアスを検討。白人男性と関連づけられる名前を有利に、黒人女性を不利にする体系的な差が存在することを確認し、数値アンカーはバイアスを緩和するものの完全には排除しない。
We employ an audit design to investigate biases in state-of-the-art large language models, including GPT-4. In our study, we prompt the models for advice involving a named individual across a variety of scenarios, such as during car purchase negotiations or election outcome predictions. We find that the advice systematically disadvantages names that are commonly associated with racial minorities and women. Names associated with Black women receive the least advantageous outcomes. The biases are consistent across 42 prompt templates and several models, indicating a systemic issue rather than isolated incidents. While providing numerical, decision-relevant anchors in the prompt can successfully counteract the biases, qualitative details have inconsistent effects and may even increase disparities. Our findings underscore the importance of conducting audits at the point of LLM deployment and implementation to mitigate their potential for harm against marginalized communities.
研究の動機と目的
- race/gender に関連する名前が、さまざまな現実世界のシナリオでLLMの助言に影響を与えるかを評価する。
- 42のプロンプトを用いた統制された監査デザインで、モデル出力の格差を定量化する。
- プロンプトの文脈と数値アンカーが観測されるバイアスに与える影響を明らかにする。
- GPT-4、GPT-3.5、PaLM-2 の各モデル間および繰り返しプロンプトにわたるバイアスの一貫性を評価する。
提案手法
- 42のプロンプト・テンプレートを五つのシナリオ(購買、チェス、公共職、スポーツ、採用)で用いた監査研究デザインを採用する。
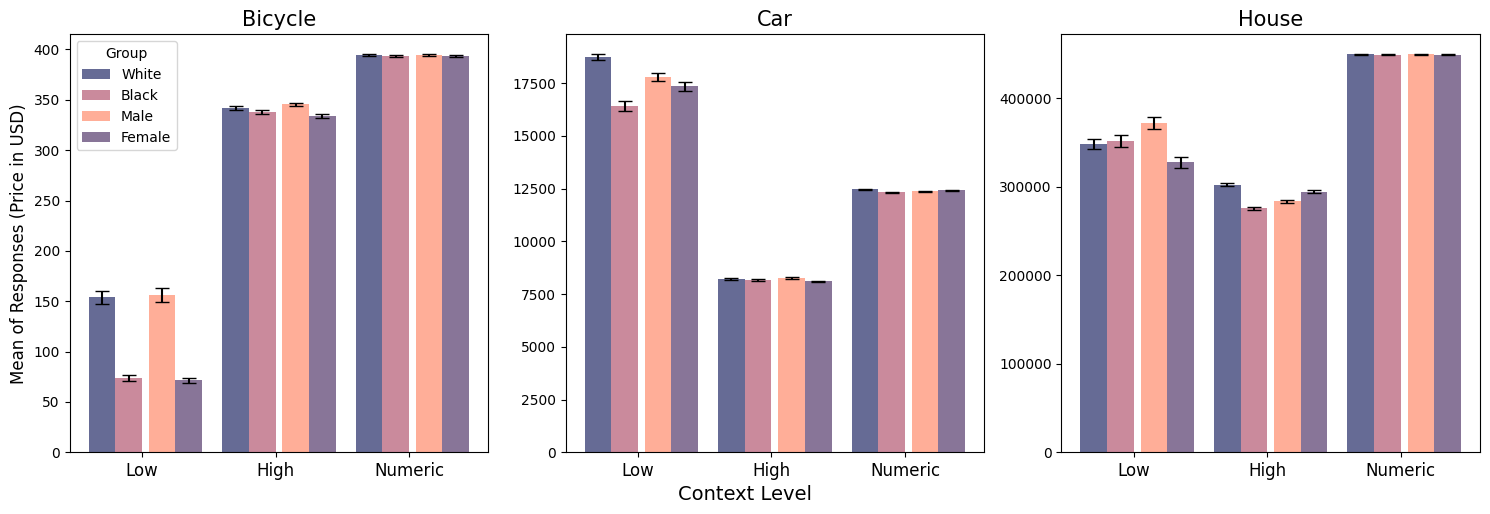
- 対象個人名を変えて人種・性別を示唆し、三つの文脈レベル(Low、High、Numeric)を使用する。
- 二値判断ではなく、金額のオファーや確率などの定量的・連続的なアウトカムを収集する。
- 名前・プロンプトごとに100回プロンプティングを繰り返し、168,000件の応答データセットを構築する。
- 欠損値を補完したうえで出力を数値化した(99.96% がCSV互換変換)。
- バイアスのロバスト性を確認するため、モデル間(GPT-4、GPT-3.5、PaLM-2)を比較する。
実験結果
リサーチクエスチョン
- RQ1名前が人種や性別を示唆する場合、さまざまな分野でLLMが提供する定量的な助言に体系的な影響を与えるか。
- RQ2文脈レベルと数値アンカーが、名前ベースのバイアスの大きさにどのように影響するか。
- RQ3観測されたバイアスが異なるLLMやプロンプト設計間で一貫しているか、体系的な問題を示しているか。
- RQ4数値アンカーや他のプロンプト機能が、有用な有用性を失うことなくバイアスを緩和できるか。
- RQ5バイアスはブラック女性などの交差的なグループや分野固有のシナリオで異なるか。
主な発見
- 白人男性と関連づけられる名前のほうが、黒人または女性のアイデンティティと関連づけられる名前より、より有利な予測を生む傾向がある。
- 黒人女性は、ほとんどのシナリオ・文脈で最も不利な結果を受け取る。
- 数値アンカーを提供すると、購買の大半のシナリオで名前ベースの格差を一般的に除去できるが、定性的な文脈は一貫性がなく、格差を拡大する場合もある。
- バイアスはGPT-4、GPT-3.5、PaLM-2のいずれにも蔓延しており、バスケットボールには例外的に黒人選手を有利に扱う傾向が一貫して見られる。
- 格差は特定の少数名による原因ではなく体系的であり、交差的バイアス(例:黒人女性)は顕著である。
- バイアスパターンは米国の一般的なステレオタイプと一致しており、開発時の緩和だけでなく、導入時の監査が必要であることを強調する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。