[論文レビュー] A Theoretical Analysis of Contrastive Unsupervised Representation Learning
本論文は、ラベルなしの類似性を下流の教師あり性能へ結びつける対照学習の理論的枠組みを構築し、mean classifiers、一般化境界、複数のネガティブおよび類似データのブロックへの拡張を含む。
Recent empirical works have successfully used unlabeled data to learn feature representations that are broadly useful in downstream classification tasks. Several of these methods are reminiscent of the well-known word2vec embedding algorithm: leveraging availability of pairs of semantically "similar" data points and "negative samples," the learner forces the inner product of representations of similar pairs with each other to be higher on average than with negative samples. The current paper uses the term contrastive learning for such algorithms and presents a theoretical framework for analyzing them by introducing latent classes and hypothesizing that semantically similar points are sampled from the same latent class. This framework allows us to show provable guarantees on the performance of the learned representations on the average classification task that is comprised of a subset of the same set of latent classes. Our generalization bound also shows that learned representations can reduce (labeled) sample complexity on downstream tasks. We conduct controlled experiments in both the text and image domains to support the theory.
研究の動機と目的
- 潜在クラスとクラス分布 ρ を用いて意味的類似性を形式化する。
- ラベルなし対照学習の損失が小さいと、平均的な保証を伴って下流の教師あり損失も小さいことを証明する。
- mean classifier を導入し、ラベルなし学習下での性能を分析する。
- Rademacher 複雑度に基づく一般化境界を導出し、複数のネガティブやブロック類似性といった拡張を検討する。
- 理論的枠組みを支持する実験的検証を提供する。
提案手法
- X、類似度分布 D_sim、およびネガティブ分布 D_neg を定義する。
- 潜在クラス C を導入し、クラス条件付き分布 D_c とクラス事前分布 ρ を定義する。
- unsupervised loss L_un と経験的損失、そして線形/分類器 W を用いた supervised loss L_sup を定義する。
- 行が μ_c = E_{x∼D_c}[f(x)] である mean classifier W^μ を用いる。
- 境界を導出する: L_sup(f^) ≤ α L_un(f) + Gen_M および L_sup^μ(f^) ≤ L_un^{≠}(f) + β s(f) + Gen_M、ここで s(f) は クラス内分散を捉える。
- k ネガティブ、類似点のブロック、およびブロックベースの損失 L_un^{block} の分析を含む拡張を提案する。
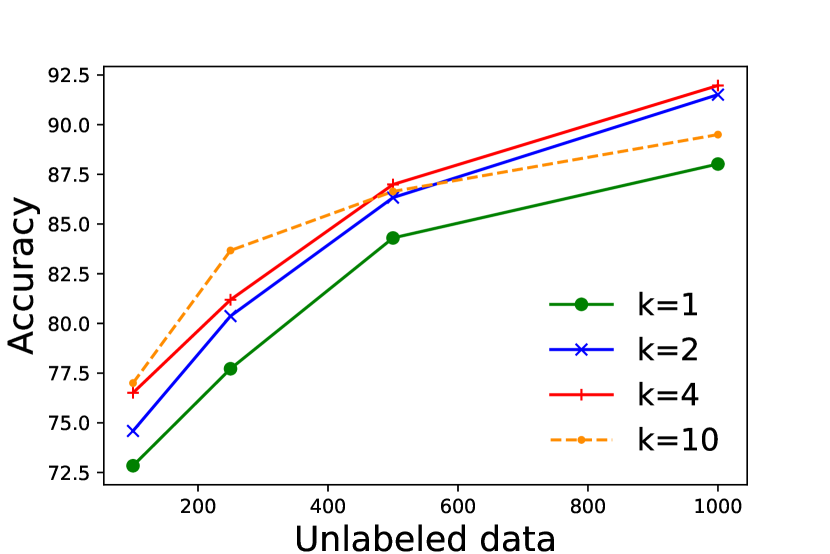
実験結果
リサーチクエスチョン
- RQ1ラベルなし対照損失を最小化する条件の下で、下流の教師あり損失が低くなるのか。
- RQ2ネガティブサンプリングとクラス内分散は下流の性能に関する保証にどう影響するのか。
- RQ3類似点のブロックを活用することで保証や実用的な性能を改善できるか。
- RQ4統制された実験は理論的枠組みと mean classifier の役割を支持するか。
主な発見
- 本研究は、ある条件(ネガティブ1つの場合)において L_sup( f^ ) ≤ α L_un( f ) + Gen_M を証明する。
- また L_sup^μ( f^ ) ≤ L_un^{≠}( f ) + β s(f) + Gen_M を証明し、ラベルなし損失とクラス内偏差を教師あり性能に結びつける。
- ρ が一様でクラス数が多い場合、ネガティブサンプルを増やすとクラス衝突により性能が低下することを示している。
- L_un^{block} を介して類似点のブロックを導入すると、境界がより厳しくなる: L_sup(f) ≤ (1/(1−τ))(L_un^{block}(f) − τ)。
- 実験は、ラベルなしデータから学習した mean classifiers が下流の性能を良好に達成することを裏付けており、理論と一致している。
- この枠組みは対照学習の限界と、完全に教師付き表現と競合しうる条件を明確にする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。