[論文レビュー] Can GPT-4 Support Analysis of Textual Data in Tasks Requiring Highly Specialized Domain Expertise?
GPT-4は、注釈ガイドラインを与えられた場合、法的文言分析においてよく訓練された法学部生の注釈者と同等の性能を示し、バッチ予測を低コストで実行できる。ただし、チェーン・オブ・思考プロンプトは限定的な利益しかもたらさず、モデルの脆さが懸念される。
We evaluated the capability of generative pre-trained transformers~(GPT-4) in analysis of textual data in tasks that require highly specialized domain expertise. Specifically, we focused on the task of analyzing court opinions to interpret legal concepts. We found that GPT-4, prompted with annotation guidelines, performs on par with well-trained law student annotators. We observed that, with a relatively minor decrease in performance, GPT-4 can perform batch predictions leading to significant cost reductions. However, employing chain-of-thought prompting did not lead to noticeably improved performance on this task. Further, we demonstrated how to analyze GPT-4's predictions to identify and mitigate deficiencies in annotation guidelines, and subsequently improve the performance of the model. Finally, we observed that the model is quite brittle, as small formatting related changes in the prompt had a high impact on the predictions. These findings can be leveraged by researchers and practitioners who engage in semantic/pragmatic annotations of texts in the context of the tasks requiring highly specialized domain expertise.
研究の動機と目的
- GPT-4が裁判所意見を法的概念の解釈のために分析する能力を、人間の注釈者と比較して評価する。
- 単一文の評価に代わる費用対効果の高い選択肢として、バッチ予測を検討する。
- この専門的なタスクにおいて、チェーン・オブ・思考(CoT) promptingが精度を向上させるか評価する。
- 注釈ガイドラインの変更がGPT-4の性能とモデルの頑健性にどのように影響するかを調査する。
提案手法
- 注釈ガイドラインから導出したシステムプロンプトを用いて、文レベルおよびバッチラベリングを実行する。
- 裁判所の意見および法令解釈の公表済みデータセットにおける正解ラベルとGPT-4の出力を比較する。
- 費用と性能のトレードオフを評価するため、単一ラベル予測とバッチ予測を比較実験する。
- 説明を含むチェーン・オブ・思考 promptingをテストして、説明が精度を改善するか低下させるかを評価する。
- GPT-4の性能向上を特定するよう注釈ガイドラインを改良し、プロンプト変更に対する頑健性を評価する。

実験結果
リサーチクエスチョン
- RQ1RQ1: この専門的な法的タスクにおいて、GPT-4の注釈性能は人間の注釈者とどの程度比較されるか?
- RQ2RQ2: GPT-4は大幅な精度の低下なしに効果的にバッチ予測を実行できるか?
- RQ3RQ3: 説明を要請する(CoT prompting)はこのタスクでGPT-4の予測を改善するか?
- RQ4RQ4: 注釈ガイドラインの変更はGPT-4の性能にどのような影響を与えるか?
- RQ5RQ5: 実験全体で小さなプロンプト変更に対するGPT-4の予測の頑健性はどの程度か?
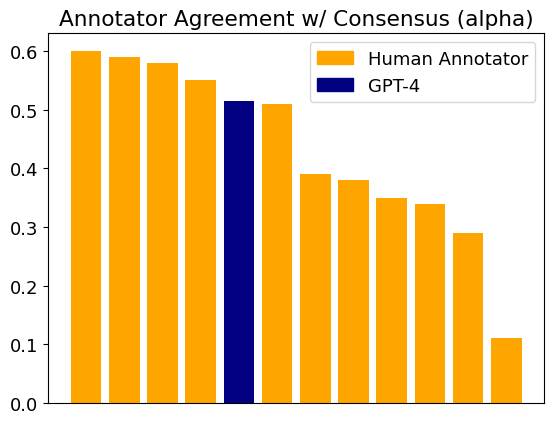
主な発見
| 指示 | 注釈モダリティ | 適合率 | 再現率 | F1スコア | 正確度 | α |
|---|---|---|---|---|---|---|
| Original | Single – Labels Only (RQ1) | .63 | .46 | .53 | .46 | .51 |
| Original | Batch – Labels Only (RQ2) | .61 | .45 | .52 | .45 | .42 |
| Original | Single – Labels & Explanation (RQ3) | .69 | .40 | .51 | .40 | .44 |
| Original | Batch – Labels & Explanation (RQ3) | .52 | .29 | .37 | .29 | .19 |
| Updated | Single – Labels Only (RQ4) | .60 | .55 | .57 | .55 | .53 |
| Updated | Batch – Labels Only (RQ4) | .57 | .46 | .51 | .46 | .42 |
| Updated | Single – Labels & Explanation (RQ4) | .58 | .57 | .57 | .57 | .48 |
| Updated | Batch – Labels & Explanation (RQ4) | .48 | .46 | .47 | .46 | .27 |
- GPT-4の全体F1は0.53であり、元の指示で単一ラベルを予測した場合、このデータセットで人間の法学部生と同等の性能。
- バッチ予測はF1が0.52で、単一ポイント予測よりわずかに低い性能だが、コストは大幅に削減。
- 元のガイドライン下では説明付きのプロンプト(CoT)は性能を向上させず、特にバッチ設定で結果を劣化させる可能性がある。
- 注釈ガイドライン(プロンプト)を改良すると、単一ラベルのF1が0.57に向上し、以前に観察された特定の誤ラベル問題を減らす。
- 更新されたガイドラインと説明を用いたバッチ予測は結果が混在し、いくつかの構成は性能を維持する一方、他は劣化させる。プロンプト変更に対する頑健性は依然課題。
- GPT-4の予測は脆弱で、プロンプトの小さなフォーマット変更が結果に大きな影響を与える。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。