[論文レビュー] FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search
FBNetは differentiable neural architecture search を用いてハードウェア認識型ConvNetを設計し、ターゲットデバイス向けに高い精度・低待機時間・探索コストの削減を実現します。FBNet-BはImageNetでトップ1 74.1%、FLOPs 295M、Samsung S8で23.1 msを達成し、従来のNAS手法と比較して探索コストが大幅に低くなっています。
Designing accurate and efficient ConvNets for mobile devices is challenging because the design space is combinatorially large. Due to this, previous neural architecture search (NAS) methods are computationally expensive. ConvNet architecture optimality depends on factors such as input resolution and target devices. However, existing approaches are too expensive for case-by-case redesigns. Also, previous work focuses primarily on reducing FLOPs, but FLOP count does not always reflect actual latency. To address these, we propose a differentiable neural architecture search (DNAS) framework that uses gradient-based methods to optimize ConvNet architectures, avoiding enumerating and training individual architectures separately as in previous methods. FBNets, a family of models discovered by DNAS surpass state-of-the-art models both designed manually and generated automatically. FBNet-B achieves 74.1% top-1 accuracy on ImageNet with 295M FLOPs and 23.1 ms latency on a Samsung S8 phone, 2.4x smaller and 1.5x faster than MobileNetV2-1.3 with similar accuracy. Despite higher accuracy and lower latency than MnasNet, we estimate FBNet-B's search cost is 420x smaller than MnasNet's, at only 216 GPU-hours. Searched for different resolutions and channel sizes, FBNets achieve 1.5% to 6.4% higher accuracy than MobileNetV2. The smallest FBNet achieves 50.2% accuracy and 2.9 ms latency (345 frames per second) on a Samsung S8. Over a Samsung-optimized FBNet, the iPhone-X-optimized model achieves a 1.4x speedup on an iPhone X.
研究の動機と目的
- モバイルデバイス向けConvNet設計における精度と実際のハードウェア待機時間の乖離を是正する。
- ターゲットハードウェアに合わせたレイヤー単位のアーキテクチャを効率的に探索するDNAS(Differentiable NAS)フレームワークを開発する。
- アーキテクチャ探索を導く待機時間認識ロスと differentiable latency estimator を定義する。
- 手動設計モデルおよび他の自動探索モデルをモバイルベンチマークで上回るFBNetモデルを実証する。
提案手法
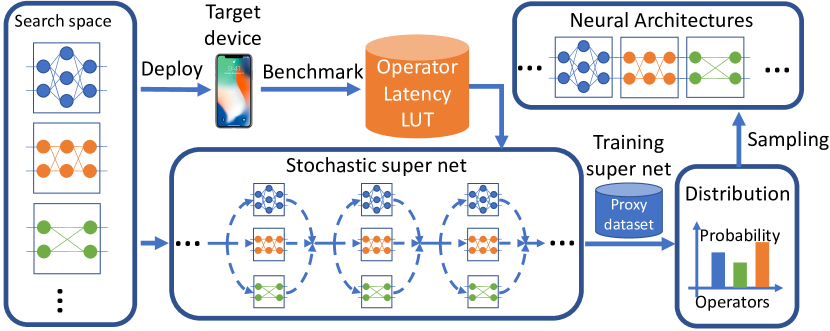
- 探索空間を22レイヤーのレイヤー別マクロアーキテクチャとして表現し、各レイヤーにつき9つの候補ブロックを持つ。
- 各レイヤーがGumbel-Softmaxを介して確率的にブロックをサンプリングする確率的スーパーネットを用い、勾配ベースの最適化を可能にする。
- LAT(a)をLAT(a)を推定できる differentiable latency lookup table により、L(a,w)=CE(a,w) * alpha * log(LAT(a))^beta の待機時間認識ロスとして定義する。
- LAT(a)=sum_l LAT(b_l^(a))として、アーキテクチャの選択に対して待機時間を微分可能にする。
- 標準的なCNNのトレーニングと同様に全オペレータの重み w_a を学習しつつ、アーキテクチャパラメータ theta を更新して高精度・低待機時間のブロックを優先する。
- 学習済み分布 P_theta から最終アーキテクチャをサンプルし、評価のために最初から訓練する。
実験結果
リサーチクエスチョン
- RQ1DNASはターゲットモバイルデバイスに合わせたハードウェア認識型ConvNetを効率的に発見できるか。
- RQ2待機時間認識の目的関数を組み込むと、精度を犠牲にすることなく実際の待機時間が低いアーキテクチャを得られるか。
- RQ3レイヤー単位のブロック柔軟性(セルレベルの再利用 vs レイヤー単位の柔軟性)は実機ハードウェア上の精度と待機時間にどのように影響するか。
- RQ4入力解像度やチャネルスケールの異なる場合に、どの程度の精度と待機時間のトレードオフが得られるか。
- RQ5デバイス固有の待機時間特性はターゲット機器ごとに別個のネットワークを正当化するか。
主な発見
| モデル | 検索 | 空間 | 検索コスト(GPU時間 / 相対) | #パラメータ | #FLOPs | CPU待機時間 | 待機時間 | Top-1 精度 (%) |
|---|---|---|---|---|---|---|---|---|
| 1.0-MobileNetV2 | manual | - | - | 3.4M | 300M | 21.7 ms | - | 72.0 |
| 1.5-ShuffleNetV2 | manual | - | - | 3.5M | 299M | 22.0 ms | - | 72.6 |
| CondenseNet (G=C=8) | manual | - | - | 2.9M | 274M | 28.4 ms | - | 71.0 |
| MnasNet-65 | RL | stage-wise | 91K ∗ / 421x | 3.6M | 270M | - | - | 73.0 |
| DARTS | gradient | cell | 288 / 1.33x | 4.9M | 595M | - | - | 73.1 |
| FBNet-A (ours) | gradient | layer-wise | 216 / 1.0x | 4.3M | 249M | 19.8 ms | - | 73.0 |
| 1.3-MobileNetV2 | manual | - | - | 5.3M | 509M | 33.8 ms | - | 74.4 |
| CondenseNet (G=C=4) | manual | - | - | 4.8M | 529M | 28.7 ms | - | 73.8 |
| MnasNet-65 | RL | stage-wise | - | 4.2M | 317M | - | - | 74.0 |
| NASNet-A | RL | cell | - | 5.3M | 564M | - | - | 74.0 |
| PNASNet | SMBO | cell | - | 5.1M | 588M | - | - | 74.2 |
| FBNet-B (ours) | gradient | layer-wise | 216 / 1.0x | 4.5M | 295M | 23.1 ms | - | 74.1 |
| 1.4-MobileNetV2 | manual | - | - | 6.9M | 585M | 37.4 ms | - | 74.7 |
| 2.0-ShuffleNetV2 | manual | - | - | 7.4M | 591M | 33.3 ms | - | 74.9 |
| MnasNet-92 | RL | stage-wise | - | 4.4M | 388M | - | - | 74.8 |
| FBNet-C (ours) | gradient | layer-wise | 216 / 1.0x | 5.5M | 375M | 28.1 ms | - | 74.9 |
- FBNetモデルは、最新のエフィシェントネットワークと比較して、待機時間とFLOPsを低く抑えつつ精度が競争的または優れている。
- FBNet-Bは Samsung S8 上で 23.1 ms の待機時間、295M FLOPs、74.1% Top-1 精度を達成し、MobileNetV2-1.3を上回り、MnasNetに迫るが探索コストははるかに低い。
- DNASは探索コストを約216 GPU-hoursまで大幅に削減し、MnasNetより約421倍速く、報告された比較でNAS/PNAS/DARTSより桁違いに高速。
- 異なる入力解像度とチャネルスケールへDNASを拡張すると、同等の待機時間下でMobileNetV2のベースラインより1.5%〜6.4%の絶対精度向上を得られる。
- FBNet-small系は非常に低い待機時間(2.9 ms程度まで)でも妥当な精度を達成し、デバイス固有の最適化(iPhone X 対 Samsung S8)によりオンデバイス速度が実質的に向上する。
- FBNet-iPhoneXおよび FBNet-S8 は、アーキテクチャの選択がデバイス特有の実行時間に適応することを示し、デバイスごとハードウェア認識設計が必要であることを実証している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。