[論文レビュー] Learning Controllable Fair Representations
この論文は、情報理論的目的を導入して、保護属性に関して制御可能な公正さを持つ最大限表現力を学習するデータ表現を提案し、表現力と公正さのバランスを取るデュアル最適化手法を提案します。
Learning data representations that are transferable and are fair with respect to certain protected attributes is crucial to reducing unfair decisions while preserving the utility of the data. We propose an information-theoretically motivated objective for learning maximally expressive representations subject to fairness constraints. We demonstrate that a range of existing approaches optimize approximations to the Lagrangian dual of our objective. In contrast to these existing approaches, our objective allows the user to control the fairness of the representations by specifying limits on unfairness. Exploiting duality, we introduce a method that optimizes the model parameters as well as the expressiveness-fairness trade-off. Empirical evidence suggests that our proposed method can balance the trade-off between multiple notions of fairness and achieves higher expressiveness at a lower computational cost.
研究の動機と目的
- 敏感属性に対する公正性制約を満たしつつ、タスク間で転用可能な表現を学習することを Aim とする。
- 相互情報量を用いて表現力と公正性を定量化し、最適化のための扱いやすい境界を導く。
- ユーザーが指定した公正性の限界と表現力と公正性のトレードオフを許容するデュアル最適化フレームワークを提供する。
提案手法
- 公正性と表現力を相互情報量の項として定式化し、I(z; u) に対するハードな制約を課す。
- Variational distributions と KL 発散を用いて I(x; z|u) および I(z; u) の扱いやすい下界と上界を導出する。
- 予測子 pψ(u|z) をモデルと共に学習させ、I(z; u) の境界を引き締める敵対的トレーニングの境界を導入する。
- I(x; z|u) の変分境界を最小化しつつ、I(z; u) を境界 C1 と hat{C2} で制約する実用的な目的関数を提案する。
- 強双対性を利用して、公正性制約を厳密に満たすようにモデルパラメータとラグランジュ乗数を最適化するデュアル最適化スキームを開発する。
- このアプローチが同じ情報理論的枠組みの特殊ケースとして、従来の公正表現法を統一的に扱えることを示す。
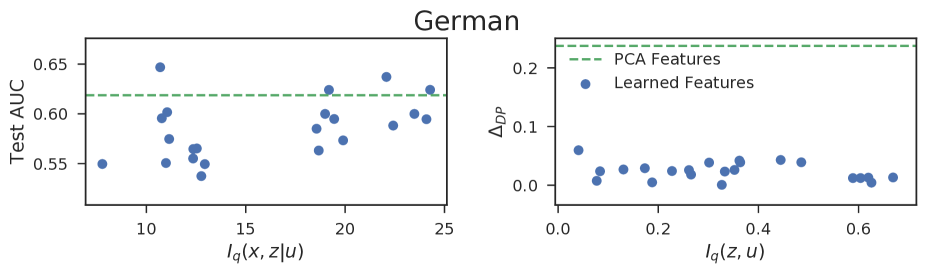
実験結果
リサーチクエスチョン
- RQ1情報理論的目的を用いて公正性制約を表現学習に組み込むにはどうすればよいか?
- RQ2学習された表現における公正性レベルを保ちつつ、下流タスクの高い表現力を維持できるか?
- RQ3デュアル最適化と敵対的境界は、固定乗数アプローチより表現力と公正性のトレードオフを改善できるか?
- RQ4デモグラフィックパリティ、等化オッズ、等化機会といった公正性の異なる概念は、相互情報量ベースの指標とどのように整合するか?
- RQ5フレームワークは複数の保護属性を二項を超えて扱えるか?
主な発見
- 提案された情報理論的目的は既存の公正性概念と整合し、公正性制約下でより表現力のある表現を生み出す。
- デュアル最適化アプローチにより、ε と適応乗数による制約を介して表現力と公正性のトレードオフを直接制御できる。
- 敵対的境界はI(z; u) の制約の厳密さを改善しつつ表現力を損なわず、複数制約の公正性制御を可能にする。
- L-MIFR(デュアル最適化)は同様の計算で MIFR(固定乗数)より表現力で上回り、グリッド探索の必要性を減らす。
- データセット全体で、公正性予算 epsilon を増やすと一般的に不公平さ (Delta DP) が増加する一方で、より情報量の高い表現を許容する。
- このフレームワークは複数の公正性概念の同時バランスをサポートする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。