[論文レビュー] Once-for-All: Train One Network and Specialize it for Efficient\n Deployment
OFAは、再 trainingなしで多様なハードウェアに対応する多様なサブネットワークへ専門化できる単一の柔軟なネットワークを訓練する。これによりデバイス間での効率的な展開と精度の維持が可能。
We address the challenging problem of efficient inference across many devices\nand resource constraints, especially on edge devices. Conventional approaches\neither manually design or use neural architecture search (NAS) to find a\nspecialized neural network and train it from scratch for each case, which is\ncomputationally prohibitive (causing $CO_2$ emission as much as 5 cars'\nlifetime) thus unscalable. In this work, we propose to train a once-for-all\n(OFA) network that supports diverse architectural settings by decoupling\ntraining and search, to reduce the cost. We can quickly get a specialized\nsub-network by selecting from the OFA network without additional training. To\nefficiently train OFA networks, we also propose a novel progressive shrinking\nalgorithm, a generalized pruning method that reduces the model size across many\nmore dimensions than pruning (depth, width, kernel size, and resolution). It\ncan obtain a surprisingly large number of sub-networks ($> 10^{19}$) that can\nfit different hardware platforms and latency constraints while maintaining the\nsame level of accuracy as training independently. On diverse edge devices, OFA\nconsistently outperforms state-of-the-art (SOTA) NAS methods (up to 4.0%\nImageNet top1 accuracy improvement over MobileNetV3, or same accuracy but 1.5x\nfaster than MobileNetV3, 2.6x faster than EfficientNet w.r.t measured latency)\nwhile reducing many orders of magnitude GPU hours and $CO_2$ emission. In\nparticular, OFA achieves a new SOTA 80.0% ImageNet top-1 accuracy under the\nmobile setting ($<$600M MACs). OFA is the winning solution for the 3rd Low\nPower Computer Vision Challenge (LPCVC), DSP classification track and the 4th\nLPCVC, both classification track and detection track. Code and 50 pre-trained\nmodels (for many devices & many latency constraints) are released at\nhttps://github.com/mit-han-lab/once-for-all.\n
研究の動機と目的
- 多様なハードウェアへの再 trainingとコストを最小化して効率的な展開の必要性を動機づける。
- 多様なアーキテクチャ構成(深さ、幅、カーネルサイズ、解像度)をサポートする単一のOnce-for-Allネットワークを導入する。
- 各展開シナリオごとに再訓練なしで高精度なサブネットワークを得ることができる訓練方式を提案する。
提案手法
- 深さ、幅、カーネルサイズ、解像度を含む弾性アーキテクチャ空間を定義し、サブネットワークへのマッピングを行う。
- 重みを共有しつつ、徐々に小さなサブネットワークをサポートするようにLarge OFAネットワークをプログレッシブシュリンクで訓練する。
- ネスト化されたサブネットワーク間の訓練を安定させるために知識蒸留を用いる。
- 特化の間、精度予測とレイテンシー参照表を備えたニューラルネットワークのツインを構築し、ハードウェア制約ごとに最適なサブネットワークを導く進化的探索を導く。
- トレーニングと探索を分離して、展開シナリオ全体でコストをO(N)からO(1)へ削減する。
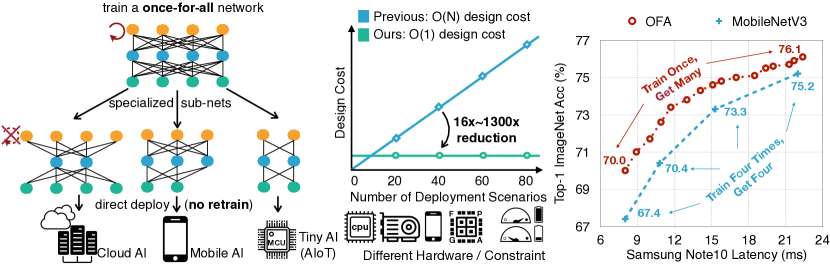
実験結果
リサーチクエスチョン
- RQ11つのOFAネットワークが、独立に訓練されたネットと同等の精度を維持しつつ、サブネットワークを非常に多数(>10^19)サポートできるか?
- RQ2プログレッシブシュリンクは、結合訓練中にサブネットワーク間の干渉を効果的に緩和できるか?
- RQ3予測子主導の探索(ニューラルネットワークのツイン)によって、多様なハードウェアに対して最適なサブネットワークをごく少ないコストで efficiently 識別できるか?
- RQ4クラウドとエッジデバイス全体で、OFAは精度、レイテンシ、エネルギー消費の観点で、最先端のハードウェア対応NAS手法と比較してどうか?
主な発見
- OFAは複数のハードウェアプラットフォームにおいて、SOTAのハードウェア認識NAS手法と比較して優れた精度-レイテンシのトレードオフを達成する。
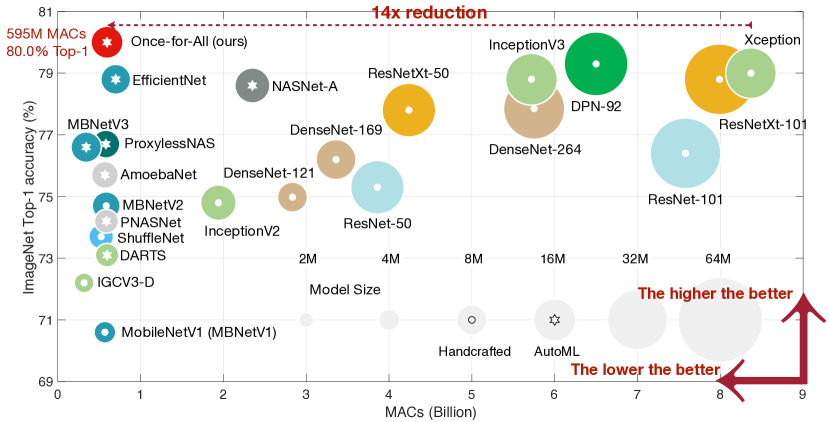
- ImageNetモバイル設定(<600M MACs)で、OFAは595M MACsで80.0%のtop-1精度を達成し、新しいモバイルSOTA。
- OFAは多数の展開シナリオをサポートする際、NASアプローチと比較して訓練・設計コストを数桁削減し、CO2排出を削減する。
- プログレッシブシュリンクにより、巨大なサブネットワーク空間(>10^19のアーキテクチャ)を効率的に訓練でき、独立訓練済みサブネットワークと同等の精度を維持する。
- さまざまなデバイス(CPU、GPU、FPGA、モバイル)での特化OFAサブネットワークは、同等のレイテンシでMobileNetV2/MnasNet/その他を一貫して上回り、ただし新しいハードウェアに対して追加トレーニングはほとんど不要。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。