[論文レビュー] Parameter Space Noise for Exploration
この論文は探索手法としてパラメータ空間ノイズを導入し、ネットワークパラメータの摂動が深層強化学習の探索を改善し、いくつかのオフポリシーおよびオンポリシーアルゴリズムでアクションスペースノイズを上回ることを示す。高次元の離散および連続タスク(スパース報酬を含む)での利点を実証し、サンプル効率の点で進化戦略と比較して有利である。
Deep reinforcement learning (RL) methods generally engage in exploratory behavior through noise injection in the action space. An alternative is to add noise directly to the agent's parameters, which can lead to more consistent exploration and a richer set of behaviors. Methods such as evolutionary strategies use parameter perturbations, but discard all temporal structure in the process and require significantly more samples. Combining parameter noise with traditional RL methods allows to combine the best of both worlds. We demonstrate that both off- and on-policy methods benefit from this approach through experimental comparison of DQN, DDPG, and TRPO on high-dimensional discrete action environments as well as continuous control tasks. Our results show that RL with parameter noise learns more efficiently than traditional RL with action space noise and evolutionary strategies individually.
研究の動機と目的
- 深層強化学習における探索課題とアクションスペースノイズの限界を動機づける。
- ニューロルポリシーの構造化探索メカニズムとしてパラメータ空間ノイズを提案する。
- オフポリシーおよびオンポリシーアルゴリズム(DQN、DDPG、TRPO)とパラメータ空間ノイズを統合する方法を示す。
- 高次元およびスパース報酬タスクでの探索の改善を実証する。
- 追加のハイパーパラメータなしにパラメータノイズを適応的にスケールするスキームを提供する。)
- method([
- パラメータ化された関数としてポリシーを表現し、パラメータベクトルをガウスノイズで摂動する: theta-tilde = theta + N(0, sigma^2 I).
- 各エピソードの開始時にポリシーを摂動し、ロールアウトの間固定して時間的構造を誘導する。
- 深層ネットワークにおいて意味のある摂動を可能にするためにレイヤー正規化を用いる。
- シグマの更新(Equation 1)を介して誘導されるアクションスペース距離を目標閾値に一致させることで適応的なノイズスケーリングを導入する。
- ノイズ付きパラメータと固定Sigma、適応スケーリングを用いた再パラメータ化トリックに従うオンポリシー手法のポリシー勾配に基づく更新を導出する(付録B/C)。
- DQN(オフポリシー)とDDPG/TRPO(オフポリシー/オンポリシー)でパラメータ空間ノイズを適用し、タスクを横断してアクションスペースノイズと比較する。
提案手法
- θ-tilde = θ + N(0, σ^2 I)を用いてパラメータ摂動。
- 各エピソードの開始時にポリシーを摂動し、ロールアウトの間固定して時間的構造を誘導する。
- 深層ネットワークにおいて意味のある摂動を可能にするためにレイヤー正規化を用いる。
- シグマの更新(Equation 1)を介して誘導されるアクションスペース距離を目標閾値に一致させることで適応的なノイズスケーリングを導入する。
- ノイズ付きパラメータと固定Sigma、適応スケーリングを用いた再パラメータ化トリックに従うオンポリシー手法のポリシー勾配に基づく更新を導出する(付録B/C)。
- DQN(オフポリシー)とDDPG/TRPO(オフポリシー/オンポリシー)でパラメータ空間ノイズを適用し、タスクを横断してアクションスペースノイズと比較する。
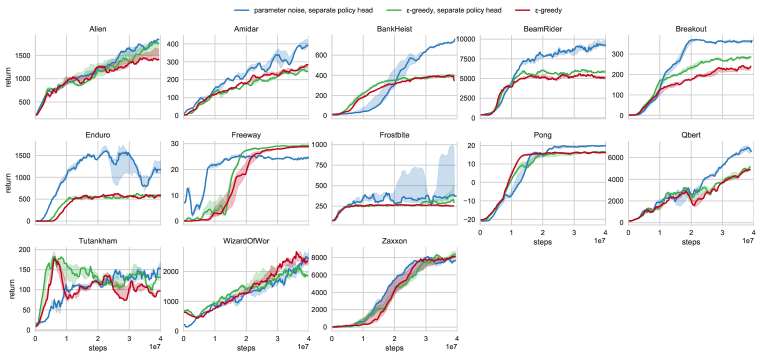
実験結果
リサーチクエスチョン
- RQ1パラメータ空間ノイズは最先端のRLアルゴリズム(DQN、DDPG、TRPO)の探索を、アクションスペースノイズと比較して改善しますか?
- RQ2アクションスペースノイズが難しいスパース報酬環境で、パラメータ空間ノイズは学習を可能にしますか?
- RQ3標準ベンチマークにおけるサンプル効率と性能の点で、パラメータ空間ノイズは進化戦略とどう比較されますか?
- RQ4安定で効果的な探索を維持するために、パラメータ空間ノイズを適応的にスケールする方法は?
- RQ5パラメータ空間ノイズはオフポリシー学習とオンポリシー学習の双方に有益ですか?
主な発見
- パラメータ空間ノイズは一貫性が重要な場合を含む高次元の離散および連続タスクで、しばしばアクションスペースノイズよりも優れている。
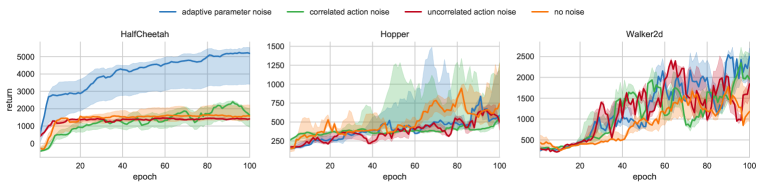
- 連続制御では、適応的なパラメータ空間ノイズがHalfCheetahの性能を著しく向上させ、Walker2Dや他のタスクで局所最適解からの脱出を助けることがある。
- パラメータ空間ノイズは、アクションスペースノイズが失敗するいくつかのスパース報酬連続タスク(例: SparseCartpoleSwingup、SparseMountainCar)で学習を可能にする。
- DDPG with parameter space noise can achieve higher returns and better exploration than uncorrelated or correlated action-space noise in key environments.
- Compared to evolution strategies, parameter space noise with 40M frames outperformed ES on 15 of 21 Atari games, despite using substantially less data, indicating better sample efficiency.
- The approach is complementary to existing improvements (e.g., double DQN, prioritized replay, dueling networks) and can be combined for further gains.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。