[論文レビュー] Noisy Networks for Exploration
NoisyNet はネットワークの重みに学習可能なパラメトリックノイズを注入して探索を促進し、DQN、Dueling、A3C の標準的な探索ヒューリスティクスを置換し、57 Atari games 全体で顕著な改善をもたらす。
We introduce NoisyNet, a deep reinforcement learning agent with parametric noise added to its weights, and show that the induced stochasticity of the agent's policy can be used to aid efficient exploration. The parameters of the noise are learned with gradient descent along with the remaining network weights. NoisyNet is straightforward to implement and adds little computational overhead. We find that replacing the conventional exploration heuristics for A3C, DQN and dueling agents (entropy reward and $ε$-greedy respectively) with NoisyNet yields substantially higher scores for a wide range of Atari games, in some cases advancing the agent from sub to super-human performance.
研究の動機と目的
- 勾配によって調整された重みの摂動によって探索と学習を結びつけるノイズベースの探索メカニズムを動機付ける。
- 複数の深層強化学習アーキテクチャにおいて、従来の探索戦略(epsilon-greedy、エントロピー報酬)を NoisyNet に置換する。
- 広範な Atari ゲームセットで性能改善を示し、学習中のノイズの適応を分析する。
提案手法
- 重みとバイアスが mu + sigma * epsilon であり、epsilon が固定分布から抽出されるノイジーネットワーク層を定義する。
- 独立ガウスノイズまたは因子分解されたガウスノイズのいずれかを用いて epsilon を生成し、スケーラブルなノイズ摂動を可能にする。
- ノイズ付きネットワーク上の損失をモンテカルロ推定しつつ、ネットワークパラメータとノイズパラメータの両方を勾配降下法で訓練する。
- 対応する線形層をノイジー層に置換し、別個の探索トリックを削除することで NoisyNet を DQN、Dueling、A3C に適用する。
- NoisyNet-DQN および NoisyNet-Dueling は各行動前にノイズを再サンプリングする。NoisyNet-A3C はエントロピー報酬を用いず、ロールアウトごとにノイズをサンプリングする。
- ノイジーなパラメータの mu および sigma の初期化スキームを提供し、NoisyNet 損失の勾配計算を詳述する。
実験結果
リサーチクエスチョン
- RQ1ニューラルネットワークに学習可能なパラメータノイズを注入することで、深層強化学習における探索効率は向上するか?
- RQ2NoisyNet は異なる深層RLアルゴリズム(DQN、Dueling、A3C)全体で従来の探索戦略を置換し、同等またはそれ以上の性能を達成できるか?
- RQ3訓練中にノイズパラメータはどのように進化し、タスクの難易度やゲームに適応するか—すなわち探索モードは文脈依存か?
- RQ4NoisyNet バリアントを使用した場合、広範な Atari ゲームでの実証的な性能向上は何か?
- RQ5ノイズ手法は、性能を犠牲にせず計算オーバーヘッドを削減するために因子分解ノイズと適合するか?
主な発見
| Baseline | NoisyNet | Improvement (on median) |
|---|---|---|
| 平均 (DQN) | 379 | 48% |
| 平均 (Dueling) | 633 | 30% |
| 平均 (A3C) | 347 | 18% |
| 中央値 (DQN) | 123 | |
| 中央値 (Dueling) | 172 | |
| 中央値 (A3C) | 94 |
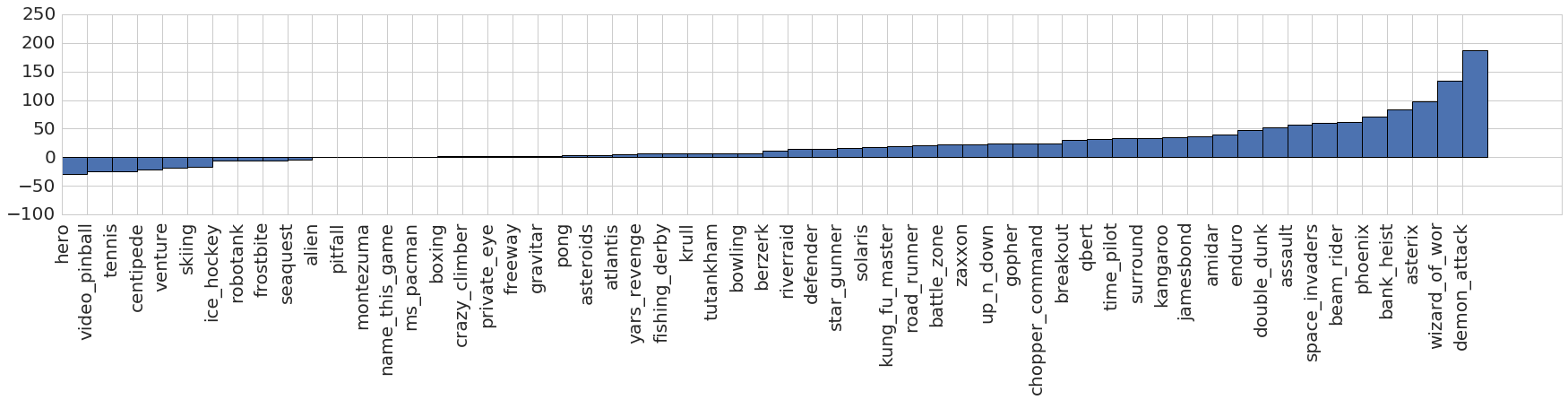
- NoisyNet バリアントは、ベースラインと比較して 57 Atari games で平均および中央値の人間正規化スコアを有意に改善する。
- DQN: 平均改善約 48%(人間正規化スコアの中央値は 83 から 123 へ改善); NoisyNet-Dueling は中央値改善 30%(132 から 172)。
- A3C は NoisyNet を用いると中央値の人間正規化スコアを 18% 向上(80 から 94)。
- いくつかのゲーム(Beam Rider、Asteroids、Freeway など)で NoisyNet はベースラインが遅れている領域で超人間的性能を達成。
- NoisyNet-A3C で因子分解ガウスノイズは計算オーバーヘッドを削減しつつ性能を維持。
- NoisyNet は収束時だけでなく訓練全体を通じて改善をもたらすことが多く、学習中の探索の強化を示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。