[論文レビュー] Retrieving Evidence from EHRs with LLMs: Possibilities and Challenges
本論文は、無監督設定(ゼロショット)で radiology 関連の診断のための非構造化EHR証拠を検索し要約するために Flan-T5 XXL の利用を検討し、LLM の出力が標準的な情報検索(IR)ベースラインより好まれる一方で幻覚が生じやすいことを示し、信頼度信号が幻覚の識別と抑制に役立つ可能性があることを示している。
Unstructured data in Electronic Health Records (EHRs) often contains critical information-complementary to imaging-that could inform radiologists' diagnoses. But the large volume of notes often associated with patients together with time constraints renders manually identifying relevant evidence practically infeasible. In this work we propose and evaluate a zero-shot strategy for using LLMs as a mechanism to efficiently retrieve and summarize unstructured evidence in patient EHR relevant to a given query. Our method entails tasking an LLM to infer whether a patient has, or is at risk of, a particular condition on the basis of associated notes; if so, we ask the model to summarize the supporting evidence. Under expert evaluation, we find that this LLM-based approach provides outputs consistently preferred to a pre-LLM information retrieval baseline. Manual evaluation is expensive, so we also propose and validate a method using an LLM to evaluate (other) LLM outputs for this task, allowing us to scale up evaluation. Our findings indicate the promise of LLMs as interfaces to EHR, but also highlight the outstanding challenge posed by "hallucinations". In this setting, however, we show that model confidence in outputs strongly correlates with faithful summaries, offering a practical means to limit confabulations.
研究の動機と目的
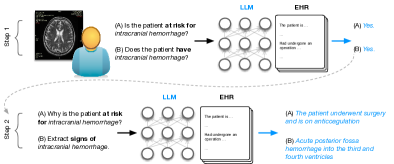
- 診断を支援するために、非構造化EHRノートとインターフェースするLLMの活用を動機づける。
- 患者が特定の状態を有するか、あるいはリスクがあるかを識別し、支持となる証拠を要約するゼロショット prompting 戦略を評価する。
- LLM ベースの検索をニューラルエンベディングのベースラインと比較し、専門家(放射線科医)による有用性と証拠の正確さを評価する。
- LLM出力における幻覚を特徴づけ、モデルの信頼度信号を潜在的な検出手段として検討する。
- EHRと連携するLLMを安全に展開する際の制限と今後の研究方向について議論する。
提案手法
- Flan-T5 XXL を基盤LLMとして用い、特定の診断に対する臨床ノートのゼロショット推論を行う。
- 逐次 prompting 戦略を適用:まず診断リスクまたは有無を判断し、陽性の場合に支持証拠を抽出する。
- リトリーバルベースライン CBERT(ニューラルエンベディング)と比較し、GPT-3.5 でリスク因子フレーズを生成、ClinicalBERT を文エンベディングに使用。
- ノートの関連性と有無を実地確認する専門の放射線科医によって証拠を評価し、0–3 の有用性スケールを使用。
- LM の尤度と自己整合性 prompting によって信頼度を分析し、幻覚を検出して有用性と相関づける。
実験結果
リサーチクエスチョン
- RQ1ゼロショットのLLMは、非構造化EHRノートから患者が特定の診断のリスクがあるか、または既に有するかを判断できるか。
- RQ2ニューラルエンベディング検索ベースラインと比較した場合、LLM生成証拠の質と忠実性はどうか。
- RQ3LLM が幻覚を生む頻度はどれくらいか、信頼度信号は幻覚を効果的に識別できるか。
- RQ4放射線科医は、証拠の提示と要約において要約的 abstractive 出力を抽出的ベースラインより好むか。
- RQ5クエリ用語の変動やデータセットソースの違いに対するアプローチの頑健性はどの程度か。
主な発見
- LLM生成の証拠は有用性と簡潔さの点で放射線科医にCBERTベースラインより好まれることが多い。
- HALA: 評価サンプルの約9.4%のFLAN-T5証拠が幻覚である。
- 放射線科医は、MIMIC で 41.5%、BWH で 48.4% の FLAN-T5 証拠を(非常に)有用と判断し、幻覚はそれぞれ 23.0%(MIMIC)と 18.5%(BWH)であった。
- モデルの信頼度スコア(尤度と自己整合性)は幻覚を高精度に識別(AUC > 0.9)し、有用性と相関する。
- ノートから将来の診断を識別する再現率は、サブセット研究で0.7(140/200 正解)を達成。
- 放射線科医は、 abstractive FLAN-T5 出力が extractive なスニペットよりもより精緻で簡潔な要約を提供すると報告。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。