[論文レビュー] Revisiting Self-Supervised Visual Representation Learning
この論文は自己教師あり視覚表現学習の大規模研究を行い、CNNアーキテクチャの選択と幅が学習表現に大きく影響することを示し、構造と前提タスクを一緒に最適化することで新たな最先端成果を達成する。
Unsupervised visual representation learning remains a largely unsolved problem in computer vision research. Among a big body of recently proposed approaches for unsupervised learning of visual representations, a class of self-supervised techniques achieves superior performance on many challenging benchmarks. A large number of the pretext tasks for self-supervised learning have been studied, but other important aspects, such as the choice of convolutional neural networks (CNN), has not received equal attention. Therefore, we revisit numerous previously proposed self-supervised models, conduct a thorough large scale study and, as a result, uncover multiple crucial insights. We challenge a number of common practices in selfsupervised visual representation learning and observe that standard recipes for CNN design do not always translate to self-supervised representation learning. As part of our study, we drastically boost the performance of previously proposed techniques and outperform previously published state-of-the-art results by a large margin.
研究の動機と目的
- CNNアーキテクチャの選択が自己教師あり視覚表現の質にどのように影響するかを評価する。
- 標準的な監督付き設計の実践が自己教師あり設定へ適用可能かを判断する。
- ネットワークの幅と可逆性が表現の質にどのように影響するかを特定する。
- 自己教師付き学習で得られた表現を評価するための線形評価の適切さを評価する。
- 自己教師なし学習の性能を向上させるためのアーキテクチャとタスクの選択に関する指針を提供する。
提案手法
- 自己教師付きタスクで、異なる幅ファクター(k)を持つ6つのCNNアーキテクチャ(ResNet系、RevNet、VGG)を評価する。
- アーキテクチャ間で4つの自己教師付き手法(Rotation、Exemplar、Relative Patch Location、Jigsaw)を再検討する。
- 事前ロジット表現を使用して、下流のImageNet/Places205タスクの線形ロジスティック回帰分類器を訓練する。
- 線形評価と非線形(MLP)評価を比較して線形プローブの適切さを評価する。
- ネットワーク幅と表現サイズの影響を独立して分析する。
- 線形評価のためのSGDトレーニングダイナミクスを検討して収束要件を理解する。
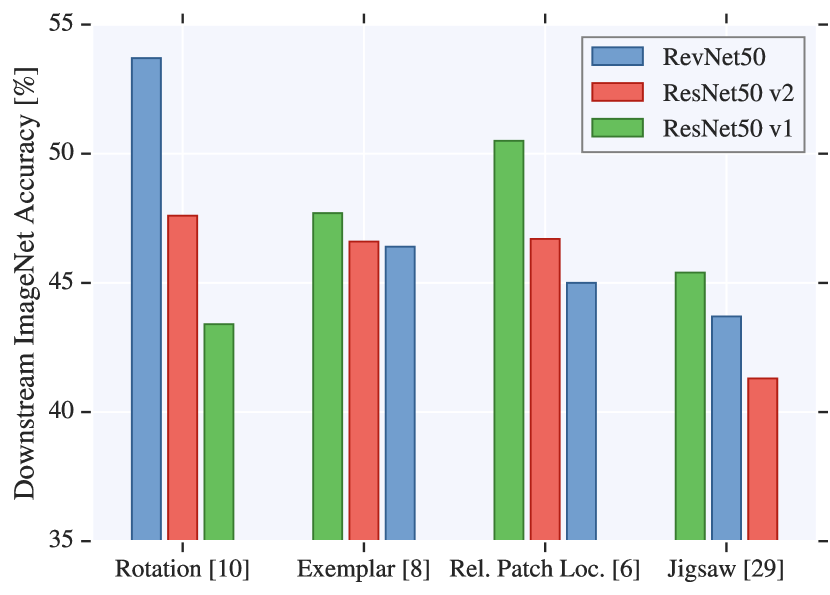
実験結果
リサーチクエスチョン
- RQ1CNNアーキテクチャは自己教師付きタスクを通じて学習される表現の品質にどのように影響するか?
- RQ2標準的な監督付き設計のCNN選択は自己教師付き設定に適用できるか?
- RQ3ネットワークの幅と表現サイズを増やすことが自己教師付き性能に与える影響は何か?
- RQ4線形評価はアーキテクチャとタスクを横断する表現品質を判断するのに十分か?
- RQ5スキップ接続と可逆性は深層ネットワークにおける有用な表現の保持にどう影響するか?
主な発見
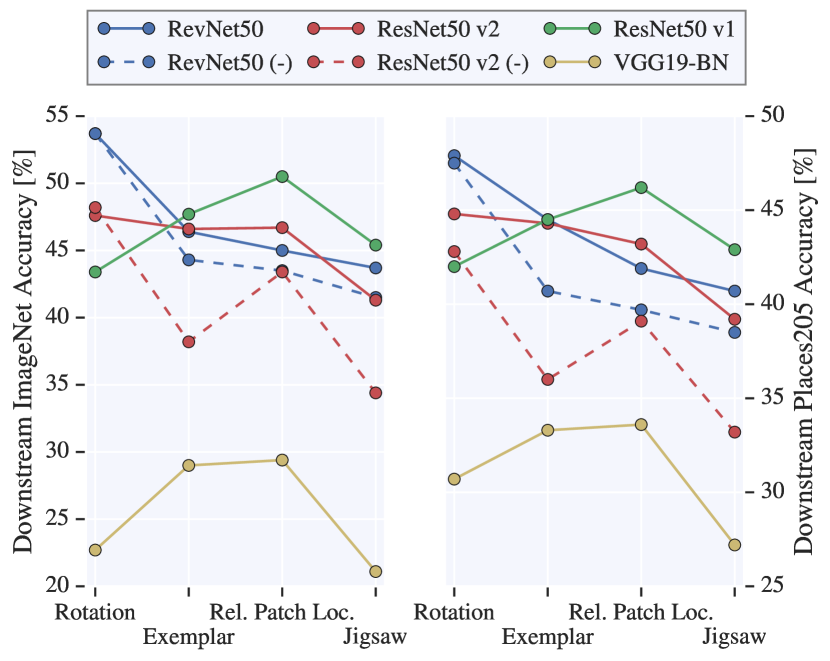
- アーキテクチャの選択は自己教師付きの性能に著しく影響し、タスクごとにランキングが異なる。
- 自己教師付き学習では深い層に向かう表現品質の劣化を防ぐのにスキップ接続が役立つ。
- フィルター数(幅)と表現サイズを増やすと一貫して性能が向上する。
- 線形評価は概ね適切であり、この文脈では非線形評価はごくわずかな改善しか生まない。
- コンテキスト予測は元々自己教師あり学習を引き起こし、適切なアーキテクチャを用いれば先端的な結果を達成できる。
- より広いモデルはデータセット(ImageNetとPlaces205)および低データ領域の両方で利益をもたらす。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。