[論文レビュー] Video Representation Learning with Visual Tempo Consistency
本論文は、階層的対比学習(VTHCL)による視覚的テンポ整合性を用いて、遅いテンポと速いテンポで同じアクション動画間の類似性を強制する自己監視付き動画表現学習を提案し、アクション認識で競争力を持ち、他タスクへの転移性を確保し、解釈のためのインスタンス対応マップを提供する。
Visual tempo, which describes how fast an action goes, has shown its potential in supervised action recognition. In this work, we demonstrate that visual tempo can also serve as a self-supervision signal for video representation learning. We propose to maximize the mutual information between representations of slow and fast videos via hierarchical contrastive learning (VTHCL). Specifically, by sampling the same instance at slow and fast frame rates respectively, we can obtain slow and fast video frames which share the same semantics but contain different visual tempos. Video representations learned from VTHCL achieve the competitive performances under the self-supervision evaluation protocol for action recognition on UCF-101 (82.1\%) and HMDB-51 (49.2\%). Moreover, comprehensive experiments suggest that the learned representations are generalized well to other downstream tasks including action detection on AVA and action anticipation on Epic-Kitchen. Finally, we propose Instance Correspondence Map (ICM) to visualize the shared semantics captured by contrastive learning.
研究の動機と目的
- 視覚的テンポが動画表現学習の自己監視信号として機能し得ることを示す。
- 複数のネットワーク深さでテンポによって誘発される意味を活用する階層的対比学習フレームワークを提案する。
- UCF-101とHMDB-51で競争力のあるアクション認識結果を示し、AVA検出とEpic-Kitchenの予測への転移性を示す。
- Instance Correspondence Mapを用いて学習表現を解釈し、共有されたインスタンス意味を明らかにする。
提案手法
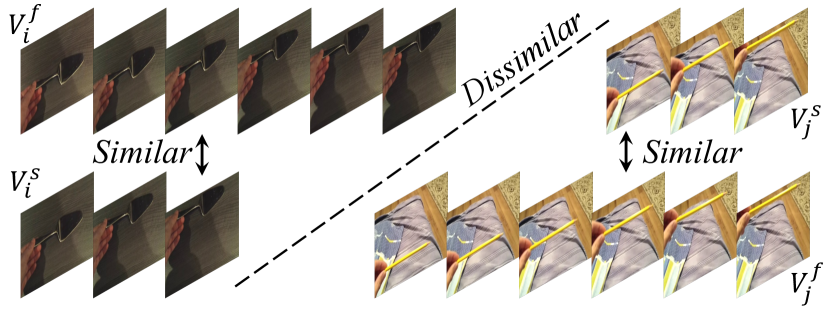
- 同じアクションインスタンスから異なるテンポで表現を抽出するために、遅いテンポと速いテンポの動画エンコーダを使用する。
- 同じインスタンスの速い表現と遅い表現の相互情報を最大化する対比学習を適用し、他のインスタンスをネガティブとして用いる。
- 複数の深さの特徴を組み込んだ階層的対比学習へ拡張し、各深さに対応するメモリバンクを導入する(例: res3, res4, res5)。
- 動量更新を伴うメモリバンク機構を用いて表現学習を安定化させる。
- 非線形写像phiと温度Tを用いて類似関数hを定義し、横断的な時間間の類似度を計算する。
- 対比目的によって捉えられた共有意味を可視化するためのInstance Correspondence Map(ICM)を導入する。
実験結果
リサーチクエスチョン
- RQ1同じアクションの2つのクリップ間での視覚的テンポの変化は、単一テンポのアプローチより強力な自己監視信号を提供するか?
- RQ2時系列深さを活用した階層型対比学習は動画表現学習を改善できるか?
- RQ3テンポ整合表現はアクション認識以外の下流タスク(検出、予測など)へどの程度転移できるか?
- RQ4ICMを介してモデルが共有インスタンス意味について学習した内容を定性的に解釈できるか?
主な発見
| 手法 | バックボーン | フレーム | UCF-101 (Top-1) | HMDB-51 (Top-1) |
|---|---|---|---|---|
| VTHCL-R18 (Ours) | 3D-ResNet18 | 8 | 80.6 | 48.6 |
| VTHCL-R50 (Ours) | 3D-ResNet50 | 8 | 82.1 | 49.2 |
- 遅いテンポと速いテンポのペアを用いたVTHCLは、UCF-101(R50でTop-1 82.1%)およびHMDB-51(R50でTop-1 49.2%)で競争力のあるアクション認識を示す。
- res3/res4/res5などの複数のネットワーク深さを用いた階層的対比学習は、単一深さの対比損失より性能を向上させる。
- 遅いクリップと速いクリップのテンポ差(alpha)を大きくすると、ベースラインの単一テンポ対比学習より精度が一般に向上する。
- VTHCL表現はAVAのアクション検出やEpic-Kitchenのアクション予測など他のタスクへ転移し、認識を超えた一般化を示す。
- ICMは、学習された表現が識別的な領域や移動する物体を局在化する定性的な可視化を提供し、ラベルなしで共有インスタンス意味を明らかにする。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。