[論文レビュー] Multi-Agent Reinforcement Learning: Methods, Applications, Visionary Prospects, and Challenges
この調査は MARL 手法、適用、および信頼できる MARL のビジョンをレビューし、安全性、頑健性、一般化、倫理的制約、そして人間-機械システムにおける人間介入を強調する。
Multi-agent reinforcement learning (MARL) is a widely used Artificial Intelligence (AI) technique. However, current studies and applications need to address its scalability, non-stationarity, and trustworthiness. This paper aims to review methods and applications and point out research trends and visionary prospects for the next decade. First, this paper summarizes the basic methods and application scenarios of MARL. Second, this paper outlines the corresponding research methods and their limitations on safety, robustness, generalization, and ethical constraints that need to be addressed in the practical applications of MARL. In particular, we believe that trustworthy MARL will become a hot research topic in the next decade. In addition, we suggest that considering human interaction is essential for the practical application of MARL in various societies. Therefore, this paper also analyzes the challenges while MARL is applied to human-machine interaction.
研究の動機と目的
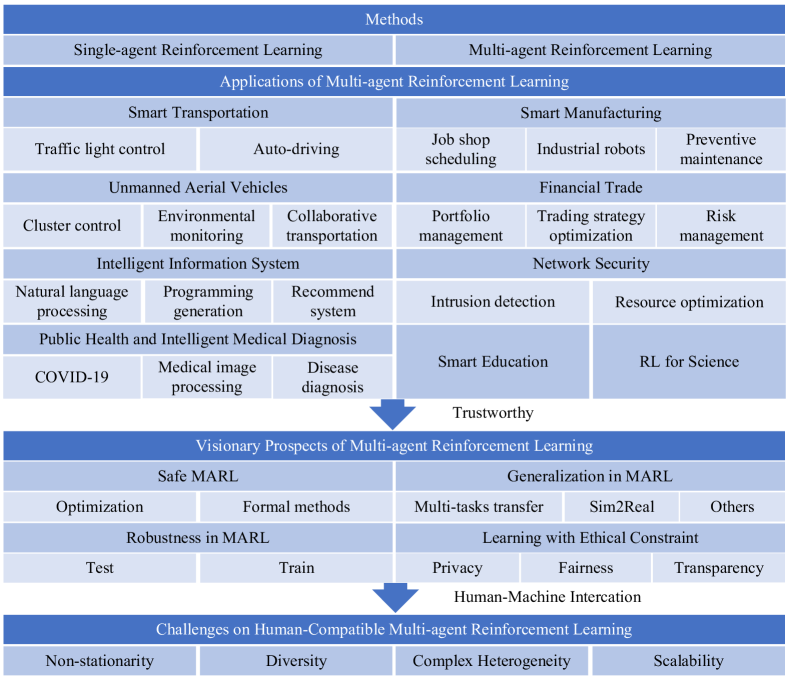
- 基本的な MARL 手法と典型的な適用シナリオを要約する。
- 実用的な MARL における安全性、頑健性、一般化、および倫理的制約を概説する。
- 現実世界のシステムにおける MARL の人間との対話の重要性を強調する。
- 今後10年間の信頼できる MARL の課題と展望を論じる。
提案手法
- 単一エージェントの RL の基礎と主要な方程式を説明する(MDP、Q-learning、DQN、policy gradient、DPG)。
- 確率的ゲームとジョイント Q/V 関数を用いた多エージェント形式を提示する。
- CTDE を含む協調の学習を議論する(VDN、QMIX、QTRAN、QPLEX、注意機構/平均場アプローチ)。
- 学習コミュニケーション手法(強化型と微分可能)とトポロジー学習を議論する。
- 平均場 MARL と大規模なエージェント集団に対するスケーラビリティ戦略を概説する。
- 人間をループに取り入れた配慮と四つの信頼関連次元(安全性、頑健性、一般化、倫理的制約)に言及する。
実験結果
リサーチクエスチョン
- RQ1主な MARL の方法論的ファミリーとそれらのトレーニングパラダイムは何か?
- RQ2MARL はどの適用分野に適用され、どの方法論的選択がされているか?
- RQ3MARL における安全性、頑健性、一般化、倫理的制約の主要な制約は何か?
- RQ4実用的な人機システムのために人間の介入を MARL に統合するにはどうすればよいか?
- RQ5来後10年間における信頼できる MARL を定義する課題と展望は何か?
主な発見
- 協調 MARL における集中訓練と分散実行 (CTDE) が支配的なパラダイムである。
- 価値ベースの手法(VDN、QMIX、QTRAN、QPLEX)と方策ベースの手法(MADDPG および注意機構を用いた変種)は、クレジット割り当てと MARL のスケーラビリティに対処する。
- 学習通信(強化型および微分可能)とグラフベース/トポロジー認識アプローチは、多エージェント設定での協調を改善する。
- 平均場 MARL は平均効果や近傍ベースの観測で相互作用を近似することにより、大規模なエージェント集団へのスケーラビリティを提供する。
- 適用範囲はスマート交通、UAV、知的情報システム、製造、金融などであり、 MARL の多様性と人間をループに取り入れる必要性を示している。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。