[論文レビュー] Recent Advances in Named Entity Recognition: A Comprehensive Survey and Comparative Study
本調査は、グラフベース、トランスフォーマー系モデル、LLM、低資源手法を含む近年のNERアプローチをレビューし、人気フレームワークのデータセット間比較を提供する。
Named Entity Recognition seeks to extract substrings within a text that name real-world objects and to determine their type (for example, whether they refer to persons or organizations). In this survey, we first present an overview of recent popular approaches, including advancements in Transformer-based methods and Large Language Models (LLMs) that have not had much coverage in other surveys. In addition, we discuss reinforcement learning and graph-based approaches, highlighting their role in enhancing NER performance. Second, we focus on methods designed for datasets with scarce annotations. Third, we evaluate the performance of the main NER implementations on a variety of datasets with differing characteristics (as regards their domain, their size, and their number of classes). We thus provide a deep comparison of algorithms that have never been considered together. Our experiments shed some light on how the characteristics of datasets affect the behavior of the methods we compare.
研究の動機と目的
- NERタスクとドメイン横断の応用を定義する。
- 現代のNER手法を調査・分類し、トランスフォーマーとLLMsを強調する。
- 低資源/低アノテーション設定向けの手法を強調する。
- 多様なデータセットにわたる人気NERフレームワークの実験的比較を提供する。
提案手法
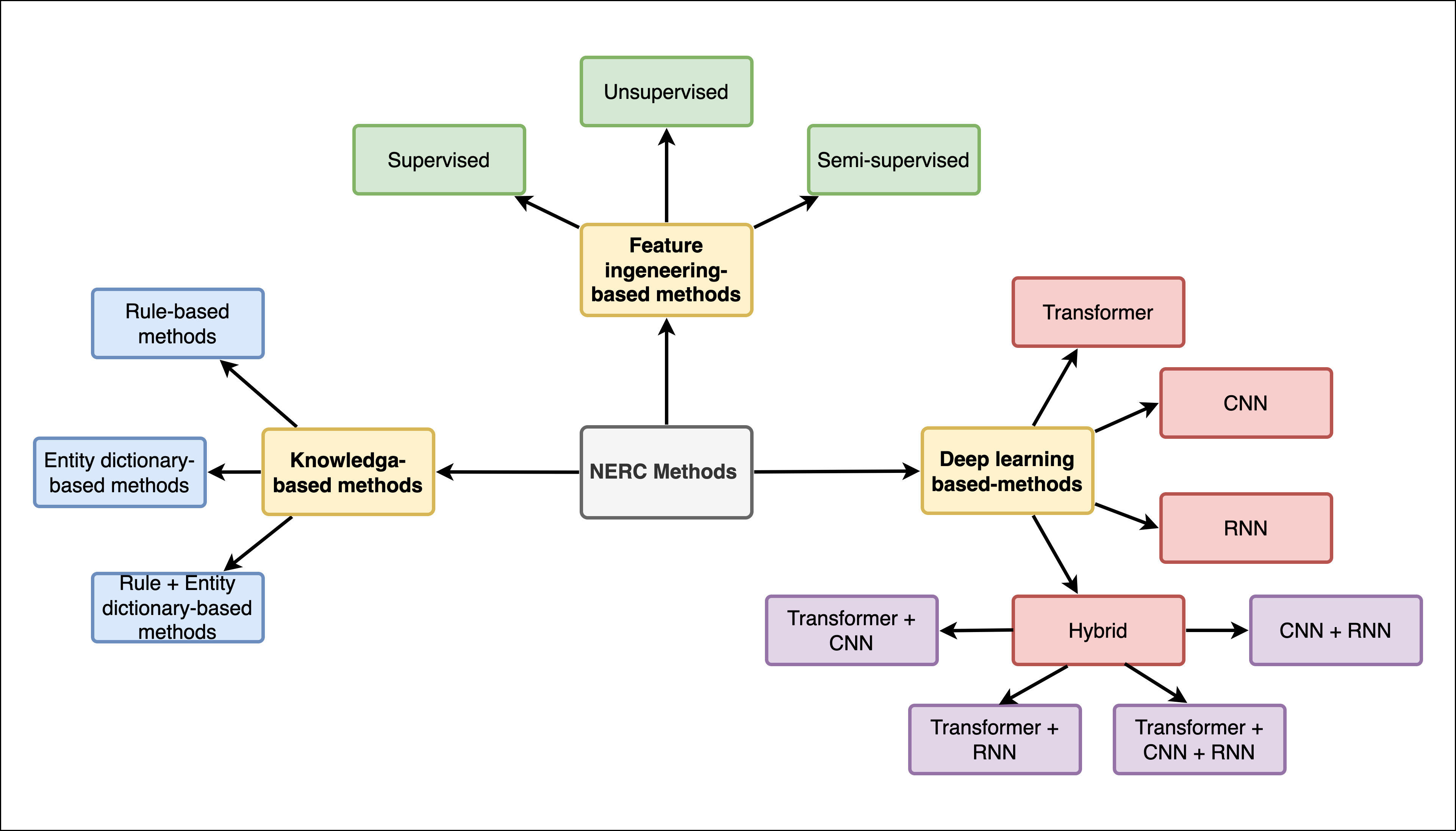
- 手法を、知識ベース、特徴量エンジニアリング、監督あり、深層学習(CNN/RNN/ハイブリッド)、トランスフォーマー系エンコーダー、そして大規模言語モデル(LLM)アプローチに分類する。
- 語彙・文字埋め込みを含むデータ表現と、文脈エンコーディング戦略(CNN、RNN、BiLSTM、トランスフォーマー)を説明する。
- CRF、MLP、ポインタネットワークなどのタグデコーディングアーキテクチャを検討し、それらが系列ラベリングに与える影響を解説する。
- トランスフォーマー系モデル(BERT、DistilBERT、RoBERTa)と、NERへの適用、マルチリンガルおよびドメイン特化のファインチューニングを含む適応を要約する。
- テキスト生成の枠組み、Few-shotプロンプトなど、LLMベースのNERアプローチを説明し、観察結果を含む研究の表を提示する。
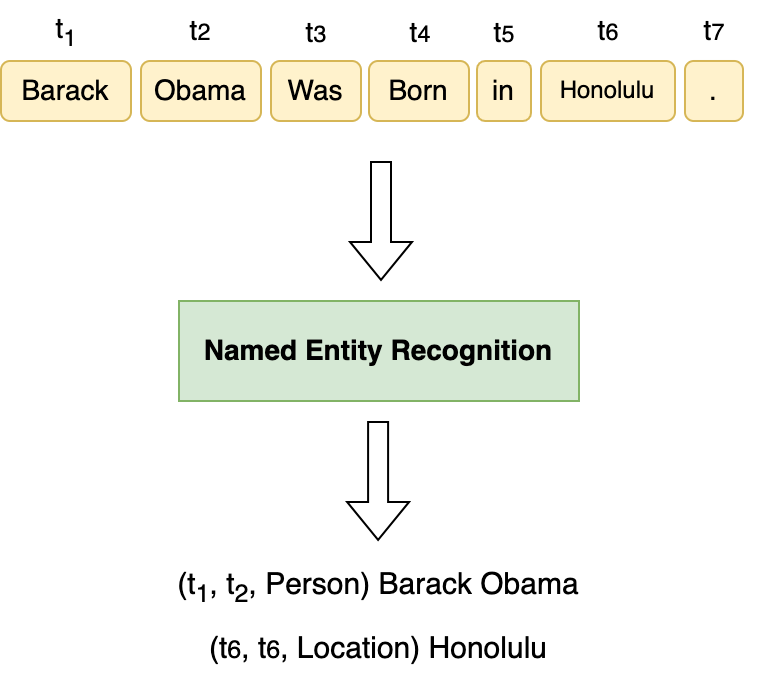
実験結果
リサーチクエスチョン
- RQ1NERにおける支配的な方法論的傾向(知識ベース、監督、深層学習、トランスフォーマー、LLMs)は何か、そしてどのように進化してきたか?
- RQ2データセットの特徴(ドメイン、サイズ、クラス数)はNER手法の相対的な性能にどう影響するか?
- RQ3低資源またはアノテーションが乏しい文脈におけるNERの課題と有効性は?
- RQ4トランスフォーマーエンコーダーとLLMsは、言語やドメインを横断するNERタスクで、従来のアーキテクチャとどのように比較されるか?
主な発見
- The survey emphasizes the rising prominence of transformer-based encoders and LLMs in NER.
- It highlights methods tailored for low-annotation settings and discusses their performance implications.
- Experimental comparisons across datasets reveal how dataset properties influence method effectiveness.
- LLM-based NER approaches show promise in few-shot and low-resource scenarios, sometimes matching supervised baselines.
- A variety of tools and pre-trained model resources for NER are reviewed alongside evaluation schemes and corpora.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。