[論文レビュー] Swin Transformer V2: Scaling Up Capacity and Resolution
この論文は Swin Transformer を 3B パラメータおよび 1,536×1,536 の画像へスケールさせ、residual-post-norm、scaled cosine attention、および log-spaced continuous position bias を用い、自己教師付き事前学習の助けを借りて、いくつかの視覚タスクで最先端を達成します。
Large-scale NLP models have been shown to significantly improve the performance on language tasks with no signs of saturation. They also demonstrate amazing few-shot capabilities like that of human beings. This paper aims to explore large-scale models in computer vision. We tackle three major issues in training and application of large vision models, including training instability, resolution gaps between pre-training and fine-tuning, and hunger on labelled data. Three main techniques are proposed: 1) a residual-post-norm method combined with cosine attention to improve training stability; 2) A log-spaced continuous position bias method to effectively transfer models pre-trained using low-resolution images to downstream tasks with high-resolution inputs; 3) A self-supervised pre-training method, SimMIM, to reduce the needs of vast labeled images. Through these techniques, this paper successfully trained a 3 billion-parameter Swin Transformer V2 model, which is the largest dense vision model to date, and makes it capable of training with images of up to 1,536$ imes$1,536 resolution. It set new performance records on 4 representative vision tasks, including ImageNet-V2 image classification, COCO object detection, ADE20K semantic segmentation, and Kinetics-400 video action classification. Also note our training is much more efficient than that in Google's billion-level visual models, which consumes 40 times less labelled data and 40 times less training time. Code is available at \url{https://github.com/microsoft/Swin-Transformer}.
研究の動機と目的
- 言語モデルとの容量ギャップを埋めるために、 vision transformers のスケーリングを促進する。
- モデル容量を拡張する際に生じる学習の不安定性に対処する。
- 高解像度入力の事前学習と微調整の間の解像度ギャップを橋渡りする。
- 自己教師付き事前学習によって大規模なラベル付きデータセットへの依存を減らす。
提案手法
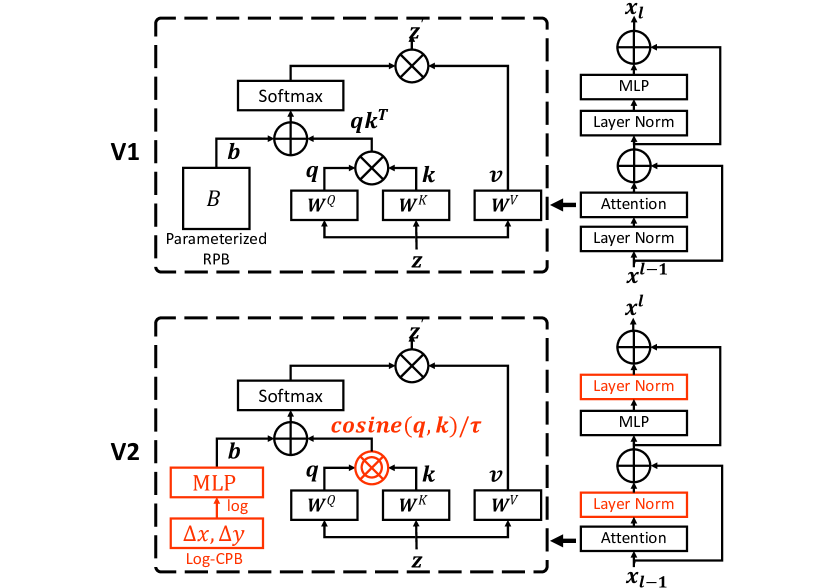
- residual post-normalization (res-post-norm) を導入し、主分岐へ戻す前に残差出力を正規化して学習を安定化させる。
- 大規模モデルで極端なアテンション値を緩和するため、ドット積アテンションをスケール付きコサインアテンションに置換する。
- 小さなメタネットワークで生成される log-spaced continuous position bias (Log-CPB) を提案し、異なるウィンドウサイズ間での転送を可能にする。
- 自己教師付き事前学習 (SimMIM) を用いてラベル付きデータへの依存を減らし、非常に大規模なモデルの訓練を可能にする。
- メモリと計算を節約する技術(ZeRO、activation checkpointing、sequential self-attention)を適用して高解像度で最大3Bパラメータの訓練を行う。
実験結果
リサーチクエスチョン
- RQ1視覚トランスフォーマーを数十億パラメータへスケールさせつつ、訓練の安定性を維持するにはどうすればよいか?
- RQ2異なる入力解像度とウィンドウサイズ間で事前学習を転送可能にするにはどうすればよいか?
- RQ3自己教師付き事前学習は大規模視覚モデルのラベル付きデータ要件を減らせるか?
- RQ4どのようなアーキテクチャと最適化戦略の組み合わせが、高解像度画像で大規模ビジョンバックボーンを効率的に訓練するのに役立つか?
主な発見
- 3B-parameter Swin Transformer V2 は複数の視覚タスクで最先端の結果を達成: ImageNet-V2 top-1 84.0%、COCO object detection 63.1/54.4 box/mask AP、ADE20K 59.9 mIoU、Kinetics-400 86.8% top-1。
- Res-post-norm とスケール付きコサインアテンションは、特に大規模モデルで安定性と精度を向上させる。
- Log-spaced continuous position bias は、ウィンドウサイズ間の効果的な転送を可能にする(小さいウィンドウでの事前学習と大きいウィンドウでの微調整を想定)。
- 自己教師付き事前学習 (SimMIM) は、ラベル付きデータを大幅に減らしても高い性能を達成(70M labeled images を使用、先行研究の約40倍に相当)。
- メモリおよび計算を節約する戦略(ZeRO、activation checkpointing、sequential self-attention)により、large models で 1,536×1,536 解像度の訓練を可能にする。
![Figure 2 : The Signal Propagation Plot [ 76 , 6 ] for various model sizes. H-size models are trained at a self-supervised learning phase, and other sizes are trained by an image classification task. * indicates that we use a 40-epoch model before it crashes.](https://ar5iv.labs.arxiv.org/html/2111.09883/assets/x2.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。