[論文レビュー] VideoBERT: A Joint Model for Video and Language Representation Learning
tldr: VideoBERTは、動画特徴を視覚語に量子化し、それをASR由来のテキストとBERT風トランスフォーマーを用いてペアリングすることで、視覚と言語を結合したモデルを訓練し、オープンボキャブラリの動画理解、ゼロショットのアクション分類、およびYouCook IIでの最先端の動画キャプション生成を実現します。
Self-supervised learning has become increasingly important to leverage the abundance of unlabeled data available on platforms like YouTube. Whereas most existing approaches learn low-level representations, we propose a joint visual-linguistic model to learn high-level features without any explicit supervision. In particular, inspired by its recent success in language modeling, we build upon the BERT model to learn bidirectional joint distributions over sequences of visual and linguistic tokens, derived from vector quantization of video data and off-the-shelf speech recognition outputs, respectively. We use VideoBERT in numerous tasks, including action classification and video captioning. We show that it can be applied directly to open-vocabulary classification, and confirm that large amounts of training data and cross-modal information are critical to performance. Furthermore, we outperform the state-of-the-art on video captioning, and quantitative results verify that the model learns high-level semantic features.
研究の動機と目的
- 共同の動画と言語モデリングを活用することで、手動ラベルなしに高レベルの意味論的な動画表現を学習できることを示す。
- 動画と言語列に対して p(x, y) を学習するために、離散的な視覚トークンを言語トークンと同様に扱えるようBERTを適応させる。
- VideoBERTがオープンボキャブラリのアクション分類をサポートし、動画キャプションタスクで従来手法を上回ることを示す。
- 大規模な事前学習データと跨モーダル情報が性能に与える影響を調査する。
- キャプショニングなどの下流タスクへのVideoBERT特徴量の転送可能性を探る。
提案手法
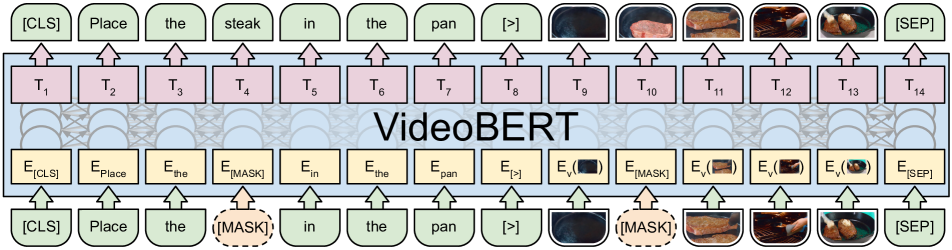
- 3D動画特徴の階層的ベクトル量子化によって得られる離散的視覚語の列として動画を表現する。
- 視覚トークンと言語トークンの両方を含む列における双方向依存関係を学ぶために、BERT風のマスクドトークン目的を用いる。
- テキストと動画の対応を教える言語-視覚整合性目的を組み込み、[CLS]表現を用いて整合を予測する。
- 英語ASRによるテキスト監督付きで大規模なYouTube料理動画データセットを用いて訓練し、BERT-LARGEのチェックポイントから初期化する。
- ゼロショットのアクション分類の確率モデルとして評価し、キャプショニングタスクの特徴抽出器として評価する。
- 事前学習データサイズを増やすと性能が単調に向上すること、跨モーダル事前学習がキャプショニングを改善することを示す。

実験結果
リサーチクエスチョン
- RQ1手動ラベルなしで、共同の視覚-言語モデルが高レベルの意味論的動画表現を学習できるか?
- RQ2BERTベースのモデルは、離散的な視覚トークンと言語トークンを一緒に扱ってオープンボキャブラリタスクを実行する能力がどの程度か?
- RQ3ビデオとテキストの跨モーダル訓練は、ビデオのみの訓練と比べて動画キャプショニングを改善するか?
- RQ4事前学習データのサイズは、学習表現と下流の性能にどのように影響するか?
- RQ5VideoBERT特徴は、動画キャプショニングや他の下流タスクへ効果的に転送できるか?
主な発見
| 方法 | 監督 | verb top-1 (%) | verb top-5 (%) | object top-1 (%) | object top-5 (%) |
|---|---|---|---|---|---|
| S3D [34] | yes | 16.1 | 46.9 | 13.2 | 30.9 |
| BERT (language prior) | no | 0.0 | 0.0 | 0.0 | 0.0 |
| VideoBERT (language prior) | no | 0.4 | 6.9 | 7.7 | 15.3 |
| VideoBERT (cross modal) | no | 3.2 | 43.3 | 13.1 | 33.7 |
- VideoBERTはYouCook IIで競争力のあるオープンボキャブラリのアクション分類を達成し、テキストのみおよび言語事前知識ベースのベースラインを上回る。
- 事前学習データサイズを増やす(10Kから300K動画へ)は、動詞/名詞認識指標で単調な利得を生む。
- VideoBERTはYouCook IIのキャプショニング指標でS3Dベースラインを上回り、跨モーダルVideoBERT (video+text) は video-only バリアントを上回る。
- VideoBERTとS3D特徴を組み合わせると、BLEU, METEOR, ROUGE-L, CIDEr のすべてで最高のキャプショニング性能を達成する。
- ゼロショットキャプショニング能力は、YouCook IIの監督なしで学習済みの視覚言語表現を活用できることを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。