[論文レビュー] CvT: Introducing Convolutions to Vision Transformers
CvTは畳み込みをVision Transformerに組み込み、階層的で畳み込み強化されたトランスフォーマを作成し、パラメータ数とFLOPsを抑えつつImageNetで最先端の結果を達成し、位置埋め込みなしでも可能である。
We present in this paper a new architecture, named Convolutional vision Transformer (CvT), that improves Vision Transformer (ViT) in performance and efficiency by introducing convolutions into ViT to yield the best of both designs. This is accomplished through two primary modifications: a hierarchy of Transformers containing a new convolutional token embedding, and a convolutional Transformer block leveraging a convolutional projection. These changes introduce desirable properties of convolutional neural networks (CNNs) to the ViT architecture (\ie shift, scale, and distortion invariance) while maintaining the merits of Transformers (\ie dynamic attention, global context, and better generalization). We validate CvT by conducting extensive experiments, showing that this approach achieves state-of-the-art performance over other Vision Transformers and ResNets on ImageNet-1k, with fewer parameters and lower FLOPs. In addition, performance gains are maintained when pretrained on larger datasets (\eg ImageNet-22k) and fine-tuned to downstream tasks. Pre-trained on ImageNet-22k, our CvT-W24 obtains a top-1 accuracy of 87.7\% on the ImageNet-1k val set. Finally, our results show that the positional encoding, a crucial component in existing Vision Transformers, can be safely removed in our model, simplifying the design for higher resolution vision tasks. Code will be released at \url{https://github.com/leoxiaobin/CvT}.
研究の動機と目的
- 局所とグローバルな文脈を活用するために、画像認識においてCNNとTransformerを組み合わせる動機を示す。
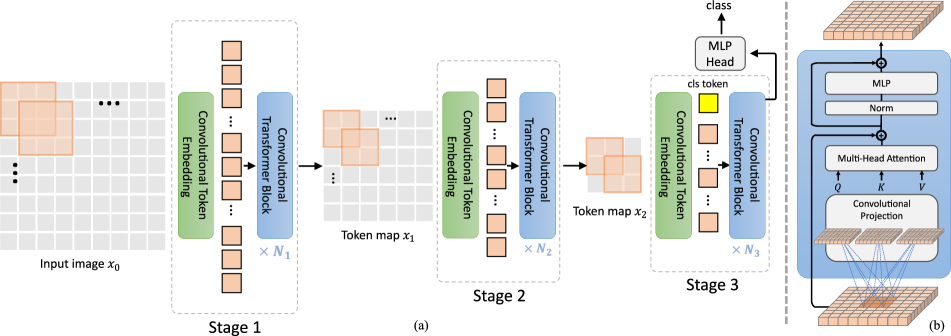
- 階層的トランスフォーマーフレームワーク内で、畳み込みトークン埋め込みと畳み込み投影という2つの中核的変更を備えたCvTを提案する。
- ImageNet-1kおよびImageNet-22kでViT/DeiTや競合するCNNと比較して精度と効率の改善を示す。
- 位置エンコーディングをパフォーマンス低下なしに除去できることを示し、可変入力解像度を可能にする。
提案手法
- 畳み込みトークン埋め込みを用いて特徴次元を増やしつつトークン長を段階的に縮小する、三段階の階層的CvTバックボーンを導入する。
- 注意入力プロジェクションを、局所的文脈をモデル化しトークンサブサンプリングを可能にする深さ方向分離畳み込みに基づく畳み込み投影に置換する。
- 畳み込みトークン埋め込みの後に層正規化を行い、最終段で標準的なMLPヘッドを適用して分類を行う。
- 畳み込みによる組み込みの局所文脈のため、位置埋め込みを削除しても性能が低下しないことを示す。
![Figure 1 : Top-1 Accuracy on ImageNet validation compared to other methods with respect to model parameters. (a) Comparison to CNN-based model BiT [ 18 ] and Transformer-based model ViT [ 11 ] , when pretrained on ImageNet-22k. Larger marker size indicates larger architectures. (b) Comparison to con](https://ar5iv.labs.arxiv.org/html/2103.15808/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1Vision Transformerへ畳み込みを導入することで、大規模画像分類で精度と効率が改善されるか?
- RQ2畳み込みトークン埋め込みと畳み込み投影を備えた階層的で多段階のCvTアーキテクチャは、ViT/DeiTやCNNを上回ることができるか?
- RQ3局所文脈が畳み込みによって捉えられる場合、明示的な位置埋め込みを性能を犠牲にせず除去することは可能か?
- RQ4CvTモデルはデータセットサイズ(例:ImageNet-1k対ImageNet-22k)に対してどのようにスケールし、下流タスクへの転移性能はどうなるか?
主な発見
| 手法タイプ | ネットワーク | #Param (M) | 画像サイズ | FLOPs (G) | ImageNet Top-1 (%) | 実測 (%) | V2 (%) |
|---|---|---|---|---|---|---|---|
| 畳み込み型トランスフォーマー(私たちの) | CvT-13 | 20 | 224^2 | 4.5 | 81.6 | 86.7 | 70.4 |
| 畳み込み型トランスフォーマー(私たちの) | CvT-21 | 32 | 224^2 | 7.1 | 82.5 | 87.2 | 71.3 |
| 畳み込み型トランスフォーマー(私たちの) | CvT-13↑384 | 20 | 384^2 | 16.3 | 83.0 | 87.9 | 71.9 |
| 畳み込み型トランスフォーマー(私たちの) | CvT-21↑384 | 32 | 384^2 | 24.9 | 83.3 | 87.7 | 71.9 |
| 畳み込み型トランスフォーマー(私たちの) | CvT-13-NAS | 18 | 224^2 | 4.1 | 82.2 | 87.5 | 71.3 |
| 畳み込み型トランスフォーマー(私たちの) | CvT-W24↑384 | 277 | 384^2 | 193.2 | 87.7 | 90.6 | 78.8 |
- CvT-21 on ImageNet-1k achieves 82.5% top-1 with 7.1G FLOPs and 32M params, outperforming DeiT-B with fewer FLOPs/parameters.
- CvT-13 achieves 81.6% top-1 with 4.5G FLOPs and 20M params, surpassing several CNN/Transformer baselines in efficiency.
- CvT-W24 pretrained on ImageNet-22k reaches 87.7% top-1 on ImageNet-1k and maintains strong transfer results on CIFAR, PETS, and Flowers.
- Removing positional embeddings from CvT does not hurt performance, highlighting that convolutional components provide sufficient spatial bias.
- NAS-inspired variants (CvT-13-NAS) can achieve comparable accuracy with fewer parameters, indicating room for architecture search gains.
- CvT shows strong performance across resolutions (e.g., 384^2) with competitive or superior accuracy to other transformers at similar or lower FLOPs.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。