[論文レビュー] Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models
本論文は、LLMs における法的ハルシネーションを、オープンドメインのケースローQAタスク一式を適用して分析し、高いハルシネーション率と、誤った法的内容を検出または修正する能力に限界があることを明らかにする。
Do large language models (LLMs) know the law? These models are increasingly being used to augment legal practice, education, and research, yet their revolutionary potential is threatened by the presence of hallucinations -- textual output that is not consistent with legal facts. We present the first systematic evidence of these hallucinations, documenting LLMs' varying performance across jurisdictions, courts, time periods, and cases. Our work makes four key contributions. First, we develop a typology of legal hallucinations, providing a conceptual framework for future research in this area. Second, we find that legal hallucinations are alarmingly prevalent, occurring between 58% of the time with ChatGPT 4 and 88% with Llama 2, when these models are asked specific, verifiable questions about random federal court cases. Third, we illustrate that LLMs often fail to correct a user's incorrect legal assumptions in a contra-factual question setup. Fourth, we provide evidence that LLMs cannot always predict, or do not always know, when they are producing legal hallucinations. Taken together, our findings caution against the rapid and unsupervised integration of popular LLMs into legal tasks. Even experienced lawyers must remain wary of legal hallucinations, and the risks are highest for those who stand to benefit from LLMs the most -- pro se litigants or those without access to traditional legal resources.
研究の動機と目的
- 未来の研究のための法的ハルシネーションの分類学を開発する。
- 検証可能な法的質問に対するLLMの回答における事実誤認の蔓延を定量化する。
- 反事実的前提の取り扱い能力を評価し、答えに対する自分の確信度を測定する。
- ケースの年齢、重要性、裁判所レベルに応じたモデルの性能変動を調査し、法的推論のモノカルチャーの潜在を識別する。
提案手法
- 存在、裁判所、引用、著者、処分、引用句、権威、覆審年、教義的一致、事実背景、手続的姿勢、後続の歴史、核心的法的問題、中心的判断という、複雑さが増す14の法的研究タスクの独自セットを作成する。
- Caselaw Access Project、最高裁データベース、その他のソースからの基礎真実メタデータを用いた参照ベースの問い合せを用いて、母集団ハルシネーション率を算出する。
- 二つの問いの paradigms: 参照ベース(根拠のある回答)と参照フリー(GPT-4 の判断を用いた矛盾ベース)
- 4つのタスクカテゴリ(低、中、高の複雑さ)にわたって、ゼロショットおよび少数ショット prompting の下で、3つのLLM(ChatGPT 3.5、PaLM 2、Llama 2)を評価する。
- 参照ベースタスクの根拠回答に対する不正解出力の割合をハルシネーション率として計算し、参照フリーの矛盾ベースタスクからの下限を計算する。
実験結果
リサーチクエスチョン
- RQ1ケースに関する検証可能な法的質問にLLMが回答する際の事実上のハルシネーションの蔓延はどの程度か?
- RQ2タスクの複雑さ、裁判所レベル、管轄、ケースの顕著さ、年次によって、異なるLLM間でハルシネーション率はどう変わるか?
- RQ3反事実バイアスにLLMsは影響を受けやすいか、法的回答に対する自分の確信度を信頼性を持って評価できるか?
- RQ4高温度の、非貪欲なプロンプトは、事実と異なる出力を示す矛盾を生み出す可能性が高いか?
主な発見
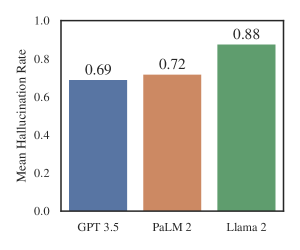
- ハルシネーションは広範で、ChatGPT 3.5の検証可能な連邦ケースの質問で69%、Llama 2で88%のクエリに観測された。
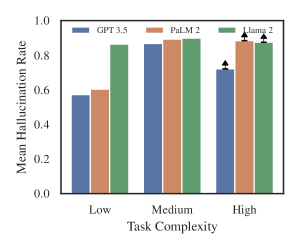
- タスクの複雑さが上がるにつれてハルシネーション率は上昇し、より新しく、より顕著で、より著名な管轄では低くなる。
- 反事実的な質問に対して誤った回答を提供するLLMsが多く、自身の確信度をポストホック再校正なしには把握するのが難しい。
- 参照フリーの手法はハルシネーション率の下限を設定し、核心的な法的問題や中心的な判断のような高複雑性タスクでは非事実的出力がかなり多い。
- より単純なタスクや高品質・著名なケースでは一般に性能が良く、LLMにおける法的モノカルチャー効果を示唆する。
- 全体として、現状のLLMsは重要な法的タスクに対して信頼できるとは言えず、特に pro se の原告など脆弱な利用者には慎重に使用すべきである。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。