[論文レビュー] REFINER: Reasoning Feedback on Intermediate Representations
REFINER は生成器を訓練して中間推論ステップを生成し、批評家を訓練して細かなフィードバックを提供することで、数学の語句問題、合成自然言語推論、道徳的ストーリー生成を横断する推論タスクを改善します。
Language models (LMs) have recently shown remarkable performance on reasoning tasks by explicitly generating intermediate inferences, e.g., chain-of-thought prompting. However, these intermediate inference steps may be inappropriate deductions from the initial context and lead to incorrect final predictions. Here we introduce REFINER, a framework for finetuning LMs to explicitly generate intermediate reasoning steps while interacting with a critic model that provides automated feedback on the reasoning. Specifically, the critic provides structured feedback that the reasoning LM uses to iteratively improve its intermediate arguments. Empirical evaluations of REFINER on three diverse reasoning tasks show significant improvements over baseline LMs of comparable scale. Furthermore, when using GPT-3.5 or ChatGPT as the reasoner, the trained critic significantly improves reasoning without finetuning the reasoner. Finally, our critic model is trained without expensive human-in-the-loop data but can be substituted with humans at inference time.
研究の動機と目的
- 言語モデルにおける中間推論ステップの明示的な生成を動機付け・可能にし、誤った推定を緩和する。
- 中間表現に対して細かなフィードバックを提供する生成器と批評家の相互作用ループを提案する。
- 構造化されたフィードバックが複数のタスクとモデル規模で推論を改善することを示す。
- 訓練済みの批評家が外部の LLM(例:GPT-3.5 や ChatGPT)でも推論を高められることを実証する。
- フィードバックの役割、批評家の品質、推論時の使用のアブレーションと分析を提供する。
提案手法
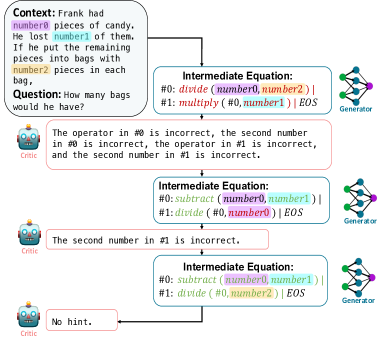
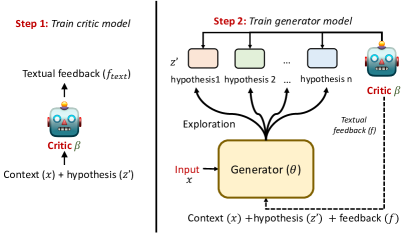
- 生成器と批評家の二モデル型 REFINER フレームワーク。
- 批評家は推論エラーを説明する自動的に構築された細粒度フィードバックデータで訓練される。
- 生成器は中間表現を生成するよう微調整され、批評家のフィードバックによって洗練される。
- フィードバックはエラー種別テンプレートから導出される半構造化テキストで、生成器向けに自然言語へ変換される。
- 訓練時の探索は核サンプリングを用いて生成器を多様なフィードバックに露出させる。
- 推論時には訓練済みの批評家を用いて生成器の中間ステップを誘導または訂正する。
実験結果
リサーチクエスチョン
- RQ1中間推論ステップの細粒度・構造化フィードバックは、スカラー報酬を超えて最終タスクの性能を改善できるか?
- RQ2タスク特化型の批評家は多様な推論タスクで中間表現と最終回答を改善できるか?
- RQ3訓練済みの批評家は外部のLLM(例:GPT-3.5、ChatGPT)の微調整なしで性能を高められるか?
- RQ4REFINER は自己精練や自己整合性といった他の改善手法と比較してタスク別にどう位置づけられるか?
- RQ5不完全(ノイズの多い)批評家や推論時の使用に対して、REFINER の利得はどれだけ頑健か?
主な発見
| Model | IR (z) | Ans (y) |
|---|---|---|
| UQA-base | 34.1 | – |
| UQA-base + PPO | 31.5 | – |
| REFINER base | 47.2 | – |
| UQA-large | 46.7 | – |
| UQA-large + PPO | 48.2 | – |
| REFINER large | 53.8 | – |
| GPT-3.5 + CoT | 64.1 | 67.1 |
| GPT-3.5 + CoT + REFINER critic | 67.3 | 70.6 |
- REFINER は数学の語句問題、合成自然言語推論、道徳的ストーリー生成において、同程度の規模のベースラインより有意な利益をもたらす。
- MWP において、IR (z) は REFINER base で 47.2、REFINER large で 53.8 へ改善;GPT-3.5 + CoT + REFINER critic では 67.3 IR と 70.6 最終正解に達する。
- sNLR において、REFINER は IR を 53.8(ベースライン 46.7 から)、最終解答正解度を 53.8 へ改善し、大型モデルで +2.9 EM の UQA-base から、+6.8 EM の GPT-3.5 からの改善を示す。
- MS において、REFINER は UQA-large ベースラインに対して道徳的規範と行動関連性を約20ポイント改善し、クラスタの信頼度を表す Krippendorff の α も高い合意を示す。
- REFINER の訓練済み批評家は単独で GPT-3.5 の few-shot 推論を顕著に改善し、MWP と sNLR でそれぞれ +3.5、+6.8 のマージンを示す。
- REFINER は自己修正アプローチを上回り、CoT ベースの方法と組み合わせると改善をもたらす(Self-Consistency、ReACT)。
- アブレーションは推論時の批評 feedback の重要性と探索フェーズを示す;不完全な批評家でも利益を生み出す一方、非常にノイズの多い批評家は性能を害する可能性がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。