[論文レビュー] Training with Quantization Noise for Extreme Model Compression
本研究は Quant-Noise という正則化手法を導入する。訓練中、重みのランダムなサブセットのみを量子化してモデルを極端な量子化に耐性を持たせる(例: int4/int8 および product quantization など)。これにより、重度の圧縮下でNLPおよび画像タスクを含む最先端の精度が達成される。
We tackle the problem of producing compact models, maximizing their accuracy for a given model size. A standard solution is to train networks with Quantization Aware Training, where the weights are quantized during training and the gradients approximated with the Straight-Through Estimator. In this paper, we extend this approach to work beyond int8 fixed-point quantization with extreme compression methods where the approximations introduced by STE are severe, such as Product Quantization. Our proposal is to only quantize a different random subset of weights during each forward, allowing for unbiased gradients to flow through the other weights. Controlling the amount of noise and its form allows for extreme compression rates while maintaining the performance of the original model. As a result we establish new state-of-the-art compromises between accuracy and model size both in natural language processing and image classification. For example, applying our method to state-of-the-art Transformer and ConvNet architectures, we can achieve 82.5% accuracy on MNLI by compressing RoBERTa to 14MB and 80.0 top-1 accuracy on ImageNet by compressing an EfficientNet-B3 to 3.3MB.
研究の動機と目的
- 大きな精度低下を伴わずに極端なモデル圧縮を動機づける。
- さまざまな量子化方式に対してネットワークを頑健にする訓練時のメカニズムを開発する。
- スカラー量子化、プロダクト量子化(PQ/iPQ)、および固定小数点演算の組み合わせを可能にする。
- 完全再訓練なしで量子化モデルを改善するための後処理ステップとして Quant-Noise を調査する。
提案手法
- Quant-Noise は各前方伝播時に重みブロックのランダムな部分集合を選択し、ターゲット量子化を模倣する歪みを適用する。
- 歪み関数には固定小数点スカラー量子化およびプロダクト量子化(PQ/iPQ の代理ノイズを用いる)を含む。
- バックプロパゲーションは歪んだ重みに対する勾配に対してストレートスルー推定(STE)を使用し、ノイズのないブロックには無偏勾配が作用する。
- Quant-Noise は訓練中の剪定やレイヤードロップと組み合わせて剪定および構造的スパース性を模擬できる。
- PQ を使用する場合、ノイズは選択されたサブベクターをゼロにする代理を介して実装でき、有用なサブベクトル相関を促進する。)],
- research_questions':['ランダム量子化ノイズでの訓練が、 大きな精度低下なしに極端な量子化(int4/int8、PQ/iPQ)に耐えるモデルを生み出せるか?','極端な圧縮レジーム下で、Quant-Noise は標準的な QAT に対して精度を改善するか?','すでに訓練済みのモデルに対する有効なポストトレーニング量子化の改善を Quant-Noise は可能にするか?','NLPおよび視覚タスクにおいて、PQ/iPQと固定小数点量子化および剪定の最良の組み合わせは何か?'],
- key_findings':['Quant-Noise は NLP(RoBERTaベース)および視覚タスク(EfficientNet-B3)で、量子化スキーム(int4、int8、PQ/iPQ)全体の性能を向上させる。','NLP(MNLI with RoBERTa)では、RoBERTaを14 MBに圧縮した場合Quant-Noiseなしで82.5%精度、訓練時にQuant-Noiseを用いると83.6%を達成; 量子化後の微調整でも83.6%を得る。','ImageNet の EfficientNet-B3 で、3.3 MB への圧縮は Quant-Noise 下で 80.0% の top-1 精度を達成し、圧縮後の未量子化ベースラインは 78.5%。','iPQ + Quant-Noise は ImageNet で 3.3 MB で 80.0% top-1、iPQ と int8 と Quant-Noise を組み合わせた場合 79.8%。PQ ベースの手法は最小限の精度低下で強力な圧縮を達成。','Quant-Noise は NLP で剪定と共有を組み合わせて最大 ×94 までの極端な圧縮比を可能にし、未圧縮モデルと比較して妥当な perplexities/accuracy を維持する。'],
- table_headers:[]
- table_rows:[]
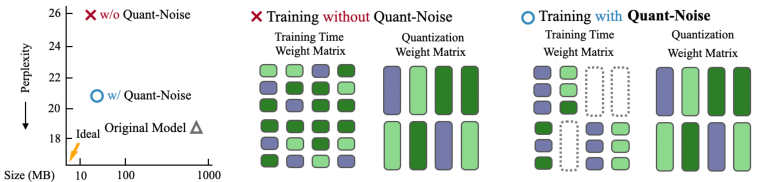
実験結果
リサーチクエスチョン
- RQ1Can training with random quantization noise yield models robust to extreme quantization (int4/int8, PQ/iPQ) without large accuracy loss?
- RQ2Does Quant-Noise improve the accuracy vs. standard QAT under extreme compression regimes?
- RQ3Can Quant-Noise enable effective post-training quantization improvements on already trained models?
- RQ4What are the best combinations of PQ/iPQ with fixed-point quantization and pruning for NLP and vision tasks?
主な発見
- Quant-Noise improves performance across quantization schemes (int4, int8, PQ/iPQ) on NLP (RoBERTa-based) and vision (EfficientNet-B3) tasks.
- On NLP (MNLI with RoBERTa), RoBERTa compressed to 14 MB achieves 82.5% accuracy without Quant-Noise, and 83.6% with Quant-Noise during training; post-training finetuning with Quant-Noise yields 83.6%.
- On ImageNet with EfficientNet-B3, compression to 3.3 MB achieves 80.0% top-1 accuracy under Quant-Noise, versus 78.5% for the unquantized baseline after compression.
- iPQ + Quant-Noise achieves 80.0% top-1 on ImageNet with 3.3 MB and 79.8% when combining iPQ with int8 and Quant-Noise; PQ-based methods reach strong compression with minimal accuracy loss.
- Quant-Noise enables extreme compression ratios (e.g., up to ×94 with pruning and sharing in NLP) while maintaining competitive perplexities/accuracy compared to uncompressed models.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。