[論文レビュー] Simple random search provides a competitive approach to reinforcement learning
著者らは、線形ポリシーのパラメータ空間での単純な augmented random search が MuJoCo 運動タスクにおけるサンプル効率で最先端と同等またはそれを上回り、Evolution Strategies よりははるかに計算効率が高いことを示している。彼らはまた、RL ベンチマークにおけるシードとハイパーパラメータ間の高い分散を強調している。
A common belief in model-free reinforcement learning is that methods based on random search in the parameter space of policies exhibit significantly worse sample complexity than those that explore the space of actions. We dispel such beliefs by introducing a random search method for training static, linear policies for continuous control problems, matching state-of-the-art sample efficiency on the benchmark MuJoCo locomotion tasks. Our method also finds a nearly optimal controller for a challenging instance of the Linear Quadratic Regulator, a classical problem in control theory, when the dynamics are not known. Computationally, our random search algorithm is at least 15 times more efficient than the fastest competing model-free methods on these benchmarks. We take advantage of this computational efficiency to evaluate the performance of our method over hundreds of random seeds and many different hyperparameter configurations for each benchmark task. Our simulations highlight a high variability in performance in these benchmark tasks, suggesting that commonly used estimations of sample efficiency do not adequately evaluate the performance of RL algorithms.
研究の動機と目的
- 探索がモデルフリーRLにおいてアクション空間探索と同等に効果的になりうるかを解明する。
- 計算効率が高い最小限の、微分自由な最適化手法を用いて線形ポリシーを訓練する。
- ARS を標準的な MuJoCo 運動ベンチマークと難しい LQR のインスタンスで評価し、シード間の性能と頑健性を確認する。
- RL ベンチマークの標準化実践を通知するため、シードとハイパーパラメータのばらつきによる性能変動を強調する。
提案手法
- RL における微分自由最適化のベースラインとして基本的なランダム探索 (BRS) を提示する。
- 報酬の標準偏差でのスケーリング、オンライン状態正規化、性能の低い方向の破棄を用いて BRS を拡張する(ARS)。
- V1, V1-t, V2, V2-t の4つの ARS 変種を導入する。V2 には状態 whitening を含み、V1/V2-t はトップ方向選択を用いる。
- 共有ノイズ表と独立したロールアウトを用いた並列実装で、ランダム方向に沿った勾配を推定する。
- RL のオラクルモデルを定式化し、環境へのロールアウト回数(クエリ)の数としてのサンプル複雑性を論じる。
- MuJoCo タスクで ARS を NG, TRPO, ES, PPO, A2C, CEM, SAC と比較し、サンプル効率と wall-clock time を分析する。
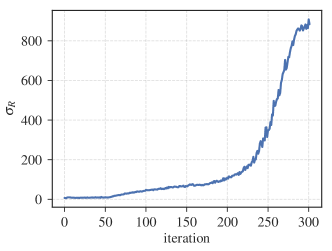
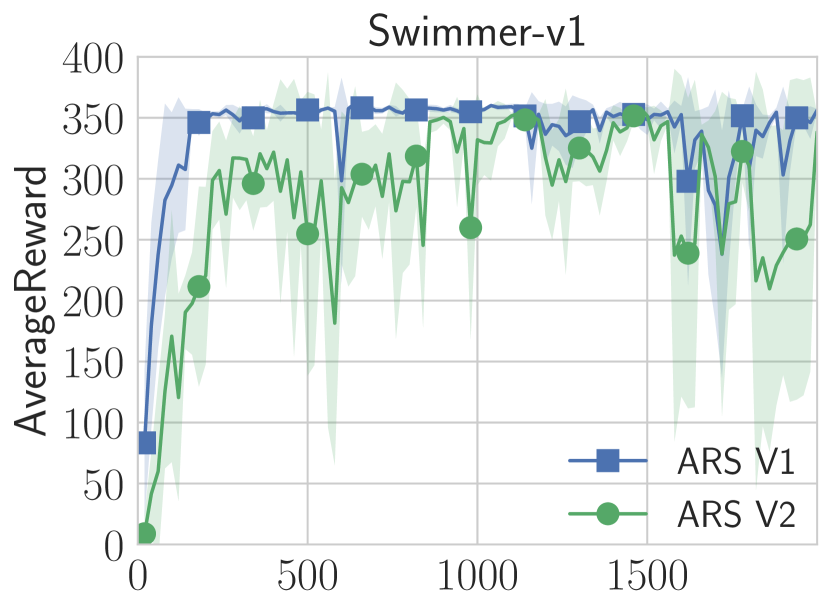
実験結果
リサーチクエスチョン
- RQ1ポリシーパラメータ空間での単純なランダム探索は連続制御タスクで競争力のあるサンプル効率を達成できるか。
- RQ2報酬スケーリング、状態正規化、トップ方向の選択といった拡張は ARS の性能を改善するか。
- RQ3MuJoCo ベンチマークにおけるサンプル効率と計算コストの観点で ARS は主流の RL 手法とどう比較されるか。
- RQ4評価シードのばらつきとハイパーパラメータ感度が RL ベンチマーク実践に与える影響は何か。
- RQ5ARS で訓練された線形ポリシーは難しい制御タスクや未知のダイナミクス問題である難しい LQR インスタンスに対して良好に機能するか。
主な発見
| タスク | 閾値 | ARS V1 | ARS V1-t | ARS V2 | ARS V2-t | NG-lin | NG-rbf | TRPO-nn |
|---|---|---|---|---|---|---|---|---|
| Swimmer-v1 | 325 | 100 | 100 | 427 | 427 | 1450 | 1550 | N/A |
| Hopper-v1 | 3120 | 89493 | 51840 | 3013 | 1973 | 13920 | 8640 | 10000 |
| HalfCheetah-v1 | 3430 | 10240 | 8106 | 2720 | 1707 | 11250 | 6000 | 4250 |
| Walker2d-v1 | 4390 | 392000 | 166133 | 89600 | 24000 | 36840 | 25680 | 14250 |
| Ant-v1 | 3580 | 101066 | 58133 | 60533 | 20800 | 39240 | 30000 | 73500 |
| Humanoid-v1 | 6000 | N/A | N/A | 142600 | 142600 | ≈130000 | ≈130000 | UNK |
- ARS は線形ポリシー(ニューラルネットワークなし)で MuJoCo 運動タスクの最先端サンプル効率と同等またはそれを超える。
- ARS は Humanoid-v1 で同等の性能閾値に到達する際、ES より少なくとも 15x 以上計算効率が高い。
- ARS はシードとハイパーパラメータ間で高い分散を示し、多くの試行を用いた広範なベンチマークの必要性を浮き彫りにする。
- ARS V2(状態正規化/ whitening を用いる) は Humanoid-v1 を解決し、V1 に比べてほとんどの MuJoCo タスクで性能を向上させる。
- ARS は未知ダイナミクス LQR 問題の難しいインスタンスをほぼ最適な性能へと解くことができる。
- 多くのベースラインと比較して、ARS は一般に良好なサンプル効率と最大報酬の競争力を 1e6 タイムステップ後に達成する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。